
I'm slowly planning the redesign of the cluster which powers the Debian Administration website.
Currently the design is simple, and looks like this:
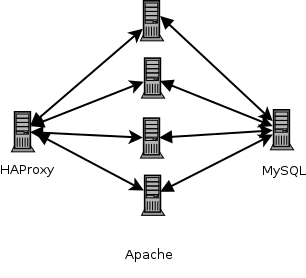
In brief there is a load-balancer that handles SSL-termination and then proxies to one of four Apache servers. These talk back and forth to a MySQL database. Nothing too shocking, or unusual.
(In truth there are two database servers, and rather than a single installation of HAProxy it runs upon each of the webservers - One is the master which is handled via ucarp. Logically though traffic routes through HAProxy to a number of Apache instances. I can lose half of the servers and things still keep running.)
When I setup the site it all ran on one host, it was simpler, it was less highly available. It also struggled to cope with the load.
Half the reason for writing/hosting the site in the first place was to document learning experiences though, so when it came to time to make it scale I figured why not learn something and do it neatly? Having it run on cheap and reliable virtual hosts was a good excuse to bump the server-count and the design has been stable for the past few years.
Recently though I've begun planning how it will be deployed in the future and I have a new design:
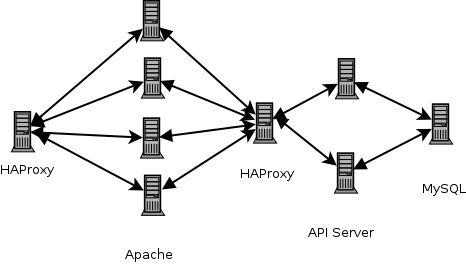
Rather than having the Apache instances talk to the database I'll indirect through an API-server. The API server will handle requests like these:
- POST /users/login
- POST a username/password and return 200 if valid. If bogus details return 403. If the user doesn't exist return 404.
- GET /users/Steve
- Return a JSON hash of user-information.
- Return 404 on invalid user.
I expect to have four API handler endpoints: /articles, /comments, /users & /weblogs. Again we'll use a floating IP and a HAProxy instance to route to multiple API-servers. Each of which will use local caching to cache articles, etc.
This should turn the middle layer, running on Apache, into simpler things, and increase throughput. I suspect, but haven't confirmed, that making a single HTTP-request to fetch a (formatted) article body will be cheaper than making N-database queries.
Anyway that's what I'm slowly pondering and working on at the moment. I wrote a proof of concept API-server based CMS two years ago, and my recollection of that time is that it was fast to develop, and easy to scale.