|
Entries tagged golang
13 September 2015 21:50
Although I've been writing a bit recently about file-storage, this post is about something much more simple: Just making a random file or two available on an ad-hoc basis.
In the past I used to have my email and website(s) hosted on the same machine, and that machine was well connected. Making a file visible just involved running ~/bin/publish, which used scp to write a file beneath an apache document-root.
These days I use "my computer", "my work computer", and "my work laptop", amongst other hosts. The SSH-keys required to access my personal boxes are not necessarily available on all of these hosts. Add in firewall constraints and suddenly there isn't an obvious way for me to say "Publish this file online, and show me the root".
I asked on twitter but nothing useful jumped out. So I ended up writing a simple server, via sinatra which would allow:
- Login via the site, and a browser. The login-form looks sexy via bootstrap.
- Upload via a web-form, once logged in. The upload-form looks sexy via bootstrap.
- Or, entirely seperately, with HTTP-basic-auth and a HTTP POST (i.e. curl)
This worked, and was even secure-enough, given that I run SSL if you import my CA file.
But using basic auth felt like cheating, and I've been learning more Go recently, and I figured I should start taking it more seriously, so I created a small repository of learning-programs. The learning programs started out simply, but I did wire up a simple TOTP authenticator.
Having TOTP available made me rethink things - suddenly even if you're not using SSL having an eavesdropper doesn't compromise future uploads.
I'd also spent a few hours working out how to make extensible commands in go, the kind of thing that lets you run:
cmd sub-command1 arg1 arg2
cmd sub-command2 arg1 .. argN
The solution I came up with wasn't perfect, but did work, and allow the seperation of different sub-command logic.
So suddenly I have the ability to run "subcommands", and the ability to authenticate against a time-based secret. What is next? Well the hard part with golang is that there are so many things to choose from - I went with gorilla/mux as my HTTP-router, then I spend several hours filling in the blanks.
The upshot is now that I have a TOTP-protected file upload site:
publishr init - Generates the secret
publishr secret - Shows you the secret for import to your authenticator
publishr serve - Starts the HTTP daemon
Other than a lack of comments, and test-cases, it is complete. And stand-alone. Uploads get dropped into ./public, and short-links are generated for free.
If you want to take a peak the code is here:
The only annoyance is the handling of dependencies - which need to be "go got ..". I guess I need to look at godep or similar, for my next learning project.
I guess there's a minor gain in making this service available via golang. I've gained protection against replay attacks, assuming non-SSL environment, and I've simplified deployment. The downside is I can no longer login over the web, and I must use curl, or similar, to upload. Acceptible tradeoff.
Tags: file-hosting, github, go, golang, sinatra
|
18 May 2016 21:50
A few months back I was looking over a lot of different object-storage systems, giving them mini-reviews, and trying them out in turn.
While many were overly complex, some were simple. Simplicity is always appealing, providing it works.
My review of camlistore was generally positive, because I like the design. Unfortunately it also highlighted a lack of documentation about how to use it to scale, replicate, and rebalance.
How hard could it be to write something similar, but also paying attention to keep it as simple as possible? Well perhaps it was too easy.
- Blob-Storage
First of all we write a blob-storage system. We allow three operations to be carried out:
- Retrieve a chunk of data, given an ID.
- Store the given chunk of data, with the specified ID.
- Return a list of all known IDs.
- API Server
We write a second server that consumers actually use, though it is implemented in terms of the blob-storage server listed previously.
The public API is trivial:
- Upload a new file, returning the ID which it was stored under.
- Retrieve a previous upload, by ID.
- Replication Support
The previous two services are sufficient to write an object storage system, but they don't necessarily provide replication. You could add immediate replication; an upload of a file could involve writing that data to N blob-servers, but in a perfect world servers don't crash, so why not replicate in the background? You save time if you only save uploaded-content to one blob-server.
Replication can be implemented purely in terms of the blob-servers:
- For each blob server, get the list of objects stored on it.
- Look for that object on each of the other servers. If it is found on N of them we're good.
- If there are fewer copies than we like, then download the data, and upload to another server.
- Repeat until each object is stored on sufficient number of blob-servers.
My code is reliable, the implementation is almost painfully simple, and the only difference in my design is that rather than having an API-server which allows both "uploads" and "downloads" I split it into two - that means you can leave your "download" server open to the world, so that it can be useful, and your upload-server can be firewalled to only allow a few hosts to access it.
The code is perl-based, because Perl is good, and available here on github:
TODO: Rewrite the thing in #golang to be cool.
Tags: dancer, golang, object-storage, perl, sos
|
19 May 2016 21:50
A couple of days ago I wrote::
The code is perl-based, because Perl is good, and available here on github:
..
TODO: Rewrite the thing in #golang to be cool.
I might not be cool, but I did indeed rewrite it in golang. It was
quite simple, and a simple benchmark of uploading two million files,
balanced across 4 nodes worked perfectly.
https://github.com/skx/sos/
Tags: golang, object-storage, sos
|
13 August 2017 21:50
I used to think I was a programmer who did "sysadmin-stuff". Nowadays I interact with too many real programmers to believe that.
Or rather I can code/program/develop, but I'm not often as good as I could be. These days I'm getting more consistent with writing tests, and I like it when things are thoroughly planned and developed. But too often if I'm busy, or distracted, I think to myself "Hrm .. compiles? Probably done. Oops. Bug, you say?"
I was going to write about working with golang today. The go language is minimal and quite neat. I like the toolset:
go fmt
- Making everything consistent.
go test
Instead I think today I'm going to write about something else. Since having a child a lot of my life is different. Routine becomes something that is essential, as is planning and scheduling.
So an average week-day goes something like this:
- 6:00AM
- 7:00AM
- Wake up Oiva and play with him for 45 minutes.
- 7:45AM
- Prepare breakfast for my wife, and wake her up, then play with Oiva for another 15 minutes while she eats.
- 8:00AM
- 8:30AM
- Make coffee, make a rough plan for the day.
- 9:00AM
- Work, until lunchtime which might be 1pm, 2pm, or even 3pm.
- 5:00PM
- Leave work, and take bus home.
- Yes I go to work via tram, but come back via bus. There are reasons.
- 5:40PM
- Arrive home, and relax in peace for 20 minutes.
- 6:00PM-7:00PM
- Take Oiva for a walk, stop en route to relax in a hammock for 30 minutes reading a book.
- 7:00-7:20PM
- Feed Oiva his evening meal.
- 7:30PM
- Give Oiva his bath, then pass him over to my wife to put him to bed.
- 7:30PM - 8:00pm
- 8:00PM - 10:00PM
- Deal with Oiva waking up, making noises, or being unsettled.
- Try to spend quality time with my wife, watch TV, read a book, do some coding, etc.
- 10:00PM ~ 11:30PM
In short I'm responsible for Oiva from 6ish-8ish in the morning, then from 6PM-10PM (with a little break while he's put to bed.) There are some exceptions to this routine - for example I work from home on Monday/Friday afternoons, and Monday evenings he goes to his swimming classes. But most working-days are the same.
Weekends are a bit different. There I tend to take him 6AM-8AM, then 1PM-10PM with a few breaks for tea, and bed. At the moment we're starting to reach the peak-party time of year, which means weekends often involve negotiation(s) about which parent is having a party, and which parent is either leaving early, or not going out at all.
Today I have him all day, and it's awesome. He's just learned to say "Daddy" which makes any stress, angst or unpleasantness utterly worthwhile.
Tags: golang, personal
|
2 November 2017 21:50
For the past few years I've hosted a service for spam-testing blog/forum comments, and I think it is on the verge of being retired.
The blogspam.net service presented a simple API for deciding whether an incoming blog/forum comment was SPAM, in real-time. I used it myself for two real reasons:
- For the Debian Administration website.
- For my blog
- Which still sees a lot of spam comments, but which are easy to deal with because I can execute Lua scripts in my mail-client
As a result of the Debian-Administration server cleanup I'm still in the process of tidying up virtual machines, and servers. It crossed my mind that retiring this spam-service would allow me to free up another host.
Initially the service was coded in Perl using XML/RPC. The current version of the software, version 2, is written as a node.js service, and despite the async-nature of the service it is still too heavy-weight to live on the host which runs most of my other websites.
It was suggested to me that rewriting it in golang might allow it to process more requests, with fewer resources, so I started reimplementing the service in golang at 4AM this morning:
The service does the minimum:
- Receives incoming HTTP POSTS
- Decodes the body to a
struct
- Loops over that struct and calls each "plugin" to process it.
- If any plugin decides this is spam, it returns that result.
- Otherwise if all plugins have terminated then it decides the result is "OK".
I've ported several plugins, I've got 100% test-coverage of those plugins, and the service seems to be faster than the node.js version - so there is hope.
Of course the real test will be when it is deployed for real. If it holds up for a few days I'll leave it running. Otherwise the retirement notice I placed on the website, which chances are nobody will see, will be true.
The missing feature at the moment is keeping track of the count of spam-comments rejected/accepted on a per-site basis. Losing that information might be a shame, but I think I'm willing to live with it, if the alternative is closing down..
Tags: blogspam, golang, node.js
|
19 March 2018 13:00
I've been thinking about serverless-stuff recently, because I've been re-deploying a bunch of services and some of them could are almost microservices. One thing that a lot of my things have in common is that they're all simple HTTP-servers, presenting an API or end-point over HTTP. There is no state, no database, and no complex dependencies.
These should be prime candidates for serverless deployment, but at the same time I don't want to have to recode them for AWS Lamda, or any similar locked-down service. So docker is the obvious answer.
Let us pretend I have ten HTTP-based services, each of which each binds to port 8000. To make these available I could just setup a simple HTTP front-end:
We'd need to route the request to the appropriate back-end, so we'd start to present URLs like:
Here any request which had the prefix steve/foo would be routed to a running instance of the docker container steve/foo. In short the name of the (first) path component performs the mapping to the back-end.
I wrote a quick hack, in golang, which would bind to port 80 and dynamically launch the appropriate containers, then proxy back and forth. I soon realized that this is a terrible idea though! The problem is a malicious client could start making requests for things like:
That would trigger my API-proxy to download the containers and spin them up. Allowing running arbitrary (albeit "sandboxed") code. So taking a step back, we want to use the path-component of an URL to decide where to route the traffic? Each container will bind to :8000 on its private (docker) IP? There's an obvious solution here: HAProxy.
So I started again, I wrote a trivial golang deamon which will react to docker events - containers starting and stopping - and generate a suitable haproxy configuration file, which can then be used to reload haproxy.
The end result is that if I launch a container named "foo" then requests to http://api.example.fi/foo will reach it. Success! The only downside to this approach is that you must manually launch your back-end docker containers - but if you do so they'll become immediately available.
I guess there is another advantage. Since you're launching the containers (manually) you can setup links, volumes, and what-not. Much more so than if your API layer span them up with zero per-container knowledge.
Tags: docker, golang, serverless
|
30 March 2018 10:00
The past couple of days I've been reworking a few of my existing projects, and converting them from Perl into Golang.
Bytemark had a great alerting system for routing alerts to different enginners, via email, SMS, and chat-messages. The system is called mauvealert and is available here on github.
The system is built around the notion of alerts which have different states (such as "pending", "raised", or "acknowledged"). Each alert is submitted via a UDP packet getting sent to the server with a bunch of fields:
- Source IP of the submitter (this is implicit).
- A human-readable ID such as "
heartbeat", "disk-space-/", "disk-space-/root", etc.
- A raise-field.
- More fields here ..
Each incoming submission is stored in a database, and events are considered unique based upon the source+ID pair, such that if you see a second submission from the same IP, with the same ID, then any existing details are updated. This update-on-receive behaviour is pretty crucial to the way things work, especially when coupled with the "raise"-field.
A raise field might have values such as:
+5m
- This alert will be raised in 5 minutes.
now
- This alert will be raised immediately.
clear
- This alert will be cleared immediately.
One simple way the system is used is to maintain heartbeat-alerts. Imagine a system sends the following message, every minute:
id:heartbeat raise:+5m [source:1.2.3.4]
- The first time this is received by the server it will be recorded in the database.
- The next time this is received the existing event will be updated, and crucially the time to raise an alert will be bumped (i.e. it will become current-time + 5m).
- The next time the update is received the raise-time will also be bumped
- ..
At some point the submitting system crashes, and five minutes after the last submission the alert moves from "pending" to "raised" - which will make it visible in the web-based user-interface, and also notify an engineer.
With this system you could easily write trivial and stateless ad-hoc monitoring scripts like so which would raise/clear :
curl https://example.com && send-alert --id http-example.com --raise clear --detail "site ok" || \
send-alert --id http-example.com --raise now --detail "site down"
In short mauvealert allows aggregation of events, and centralises how/when engineers are notified. There's the flexibility to look at events, and send them to different people at different times of the day, decide some are urgent and must trigger SMSs, and some are ignorable and just generate emails .
(In mauvealert this routing is done by having a configuration file containing ruby, this attempts to match events so you could do things like say "If the event-id contains "failed-disc" then notify a DC-person, or if the event was raised from $important-system then notify everybody.)
I thought the design was pretty cool, and wanted something similar for myself. My version, which I setup a couple of years ago, was based around HTTP+JSON, rather than UDP-messages, and written in perl:
The advantage of using HTTP+JSON is that writing clients to submit events to the central system could easily and cheaply be done in multiple environments for multiple platforms. I didn't see the need for the efficiency of using binary UDP-based messages for submission, given that I have ~20 servers at the most.
Anyway the point of this blog post is that I've now rewritten my simplified personal-clone as a golang project, which makes deployment much simpler. Events are stored in an SQLite database and when raised they get sent to me via pushover:
The main difference is that I don't allow you to route events to different people, or notify via different mechanisms. Every raised alert gets sent to me, and only me, regardless of time of day. (Albeit via an pluggable external process such that you could add your own local logic.)
I've written too much already, getting sidetracked by explaining how neat mauvealert and by extension purple was, but also I rewrote the Perl DNS-lookup service at https://dns-api.org/ in golang too:
That had a couple of regressions which were soon reported and fixed by a kind contributor (lack of CORS headers, most obviously).
Tags: dns-api.org, golang, perl, purple, purppura, rewrite
|
11 April 2018 12:01
For the past two weeks I've mostly been baking bread. I'm not sure what made me decide to make some the first time, but it actually turned out pretty good so I've been doing every day or two ever since.
This is the first time I've made bread in the past 20 years or so - I recall in the past I got frustrated that it never rose, or didn't turn out well. I can't see that I'm doing anything differently, so I'll just write it off as younger-Steve being daft!
No doubt I'll get bored of the delicious bread in the future, but for the moment I've got a good routine going - juggling going to the shops, child-care, and making bread.
Bread I've made includes the following:
Beyond that I've spent a little while writing a simple utility to embed resources in golang projects, after discovering the tool I'd previously been using, go-bindata, had been abandoned.
In short you feed it a directory of files and it will generate a file static.go with contents like this:
files[ "data/index.html" ] = "<html>....
files[ "data/robots.txt" ] = "User-Agent: * ..."
It's a bit more complex than that, but not much. As expected getting the embedded data at runtime is trivial, and it allows you to distribute a single binary even if you want/need some configuration files, templates, or media to run.
For example in the project I discussed in my previous post there is a HTTP-server which serves a user-interface based upon bootstrap. I want the HTML-files which make up that user-interface to be embedded in the binary, rather than distributing them seperately.
Anyway it's not unique, it was a fun experience writing, and I've switched to using it now:
Tags: bread, golang, implant
|
19 April 2018 12:01
The other day I had an idea that wouldn't go away, a filesystem that exported the contents of ~/.ssh/known_hosts.
I can't think of a single useful use for it, beyond simple shell-scripting, and yet I couldn't resist.
$ go get -u github.com/skx/knownfs
$ go install github.com/skx/knownfs
Now make it work:
$ mkdir ~/knownfs
$ knownfs ~/knownfs
Beneat out mount-point we can expect one directory for each known-host. So we'll see entries:
~/knownfs $ ls | grep \.vpn
builder.vpn
deagol.vpn
master.vpn
www.vpn
~/knownfs $ ls | grep steve
blog.steve.fi
builder.steve.org.uk
git.steve.org.uk
mail.steve.org.uk
master.steve.org.uk
scatha.steve.fi
www.steve.fi
www.steve.org.uk
The host-specified entries will each contain a single file fingerprint, with the fingerprint of the remote host:
~/knownfs $ cd www.steve.fi
~/knownfs/www.steve.fi $ ls
fingerprint
frodo ~/knownfs/www.steve.fi $ cat fingerprint
98:85:30:f9:f4:39:09:f7:06:e6:73:24:88:4a:2c:01
I've used it in a few shell-loops to run commands against hosts matching a pattern, but beyond that I'm struggling to think of a use for it.
If you like the idea I guess have a play:
It was perhaps more useful and productive than my other recent work - which involves porting an existing network-testing program from Ruby to golang, and in the process making it much more uniform and self-consistent.
The resulting network tester is pretty good, and can now notify via MQ to provide better decoupling too. The downside is of course that nobody changes network-testing solutions on a whim, and so these things are basically always in-house only.
Tags: fuse, golang
|
21 May 2018 12:01
This month has mostly been about golang. I've continued work on the protocol-tester that I recently introduced:
This has turned into a fun project, and now all my monitoring done with it. I've simplified the operation, such that everything uses Redis for storage, and there are now new protocol-testers for finger, nntp, and more.
Sample tests are as basic as this:
mail.steve.org.uk must run smtp
mail.steve.org.uk must run smtp with port 587
mail.steve.org.uk must run imaps
https://webmail.steve.org.uk/ must run http with content 'Prayer Webmail service'
Results are stored in a redis-queue, where they can picked off and announced to humans via a small daemon. In my case alerts are routed to a central host, via HTTP-POSTS, and eventually reach me via the pushover
Beyond the basic network testing though I've also reworked a bunch of code - so the markdown sharing site is now golang powered, rather than running on the previous perl-based code.
As a result of this rewrite, and a little more care, I now score 99/100 + 100/100 on Google's pagespeed testing service. A few more of my sites do the same now, thanks to inline-CSS, inline-JS, etc. Nothing I couldn't have done before, but this was a good moment to attack it.
Finally my "silly" Linux security module, for letting user-space decide if binaries should be executed, can-exec has been forward-ported to v4.16.17. No significant changes.
Over the coming weeks I'll be trying to move more stuff into the cloud, rather than self-hosting. I'm doing a lot of trial-and-error at the moment with Lamdas, containers, and dynamic-routing to that end.
Interesting times.
Tags: golang, linux-security-modules, markdownshare, overseer
|
2 June 2018 12:01
My previous post briefly
described the setup of system-metric collection. (At least the server-side
setup required to receive the metrics submitted by various clients.)
When it came to the clients I was complaining that collectd was too
heavyweight, as installing it pulled in a ton of packages. A kind
twitter user pointed out that you can get most of the stuff you need
via the use of the of collectd-core package:
# apt-get install collectd-core
I guess I should have known that! So for the moment that's what I'm using
to submit metrics from my hosts. In the future I will spend more time
investigating telegraf, and other "modern" solutions.
Still with collectd-core installed we've got the host-system metrics
pretty well covered. Some other things I've put together also support
metric-submission, so that's good.
I hacked up a quick package for automatically submitting metrics
to a remote server, specifically for golang applications. To use it
simply add an import to your golang application:
import (
..
_ "github.com/skx/golang-metrics"
..
)
Add the import, and rebuild your application and that's it! Configuration
is carried out solely via environmental variables, and the only one you
need to specify is the end-point for your metrics host:
$ METRICS=metrics.example.com:2003 ./foo
Now your application will be running as usual and will also be submitting
metrics to your central host every 10 seconds or so. Metrics include the
number of running goroutines, application-uptime, and memory/cpu stats.
I've added a JSON-file to import as a grafana dashboard, and you can see an example of what it looks like there too:
Tags: carbon, collectd, golang, grafana
|
16 June 2018 14:01
Recently I've had an overwhelming desire to write a BASIC intepreter. I can't
think why, but the idea popped into my mind, and wouldn't go away.
So I challenged myself to spend the weekend looking at it.
Writing an intepreter is pretty well-understood problem:
- Parse the input into tokens, such as "LET", "GOTO", "INT:3"
- This is called lexical analysis / lexing.
- Taking those tokens and building an abstract syntax tree.
- Walking the tree, evaluating as you go.
Of course BASIC is annoying because a program is prefixed by line-numbers,
for example:
10 PRINT "HELLO, WORLD"
20 GOTO 10
The naive way of approaching this is to repeat the whole process for
each line. So a program would consist of an array of input-strings each
line being treated independently.
Anyway reminding myself of all this fun took a few hours, and during the course
of that time I came across Writing an intepreter in Go which seems to be well-regarded. The book walks you through creating an interpreter for a language called "Monkey".
I found a bunch of implementations, which were nice and clean. So to give myself something to do I started by adding a new built-in function rnd(). Then I tested this:
let r = 0;
let c = 0;
for( r != 50 ) {
let r = rnd();
let c = c + 1;
}
puts "It took ";
puts c;
puts " attempts to find a random-number equalling 50!";
Unfortunately this crashed. It crashed inside the body of the loop, and it
seemed that the projects I looked at each handled the let statement in a
slightly-odd way - the statement wouldn't return a value, and would instead
fall-through a case statement, hitting the next implementation.
For example in monkey-intepreter we see that happen in this section. (Notice how there's no return after the env.Set call?)
So I reported this as a meta-bug to the book author. It might be the master
source is wrong, or might be that the unrelated individuals all made the same
error - meaning the text is unclear.
Anyway the end result is I have a language, in go, that I think I understand
and have been able to modify. Now I'll have to find some time to go back to
BASIC-work.
I found a bunch of basic-intepreters, including ubasic, but unfortunately almost all of them were missing many many features - such as implementing operations like RND(), ABS(), COS().
Perhaps room for another interpreter after all!
Tags: golang, intepreters, monkey
|
18 June 2018 12:01
So I challenged myself to writing a BASIC intepreter over the weekend,
unfortunately I did not succeed.
What I did was take an existing monkey-repl and extend it with a series of changes to make sure that I understood all the various parts of the intepreter design.
Initially I was just making basic changes:
- Added support for single-line comments.
- For example "
// This is a comment".
- Added support for multi-line comments.
- For example "
/* This is a multi-line comment */".
- Expand
\n and \t in strings.
- Allow the index operation to be applied to strings.
- For example
"Steve Kemp"[0] would result in S.
- Added a type function.
- For example "
type(3.13)" would return "float".
- For example "
type(3)" would return "integer".
- For example "
type("Moi")" would return "string".
Once I did that I overhauled the built-in functions, allowing
callers to register golang functions to make them available to their
monkey-scripts. Using this I wrote a simple "standard library" with
some simple math, string, and file I/O functions.
The end result was that I could read files, line-by-line, or even
just return an array of the lines in a file:
// "wc -l /etc/passwd" - sorta
let lines = file.lines( "/etc/passwd" );
if ( lines ) {
puts( "Read ", len(lines), " lines\n" )
}
Adding file I/O was pretty neat, although I only did reading. Handling looping
over a file-contents is a little verbose:
// wc -c /etc/passwd, sorta.
let handle = file.open("/etc/passwd");
if ( handle < 0 ) {
puts( "Failed to open file" )
}
let c = 0; // count of characters
let run = true; // still reading?
for( run == true ) {
let r = read(handle);
let l = len(r);
if ( l > 0 ) {
let c = c + l;
}
else {
let run = false;
}
};
puts( "Read " , c, " characters from file.\n" );
file.close(handle);
This morning I added some code to interpolate hash-values into a string:
// Hash we'll interpolate from
let data = { "Name":"Steve", "Contact":"+358449...", "Age": 41 };
// Expand the string using that hash
let out = string.interpolate( "My name is ${Name}, I am ${Age}", data );
// Show it worked
puts(out + "\n");
Finally I added some type-conversions, allowing strings/floats to be converted
to integers, and allowing other value to be changed to strings. With the
addition of a math.random function we then got:
// math.random() returns a float between 0 and 1.
let rand = math.random();
// modify to make it from 1-10 & show it
let val = int( rand * 10 ) + 1 ;
puts( "math.random() -> ", val , "\n");
The only other signification change was the addition of a new form of
function definition. Rather than defining functions like this:
let hello = fn() { puts( "Hello, world\n" ) };
I updated things so that you could also define a function like this:
function hello() { puts( "Hello, world\n" ) };
(The old form still works, but this is "clearer" in my eyes.)
Maybe next weekend I'll try some more BASIC work, though for the moment
I think my monkeying around is done. The world doesn't need another
scripting language, and as I mentioned there are a bunch of implementations
of this around.
The new structure I made makes adding a real set of standard-libraries
simple, and you could embed the project, but I'm struggling to think of
why you would want to. (Though I guess you could pretend you're embedding
something more stable than anko and
not everybody loves javascript as
a golang extension language.)
Tags: golang, intepreters, monkey
|
2 July 2018 12:01
I don't understand why my toy virtual machine has as much interest as it does. It is a simple project that compiles "assembly language" into a series of bytecodes, and then allows them to be executed.
Since I recently started messing around with interpreters more generally I figured I should revisit it. Initially I rewrote the part that interprets the bytecodes in golang, which was simple, but now I've rewritten the compiler too.
Much like the previous work with interpreters this uses a lexer and an evaluator to handle things properly - in the original implementation the compiler used a series of regular expressions to parse the input files. Oops.
Anyway the end result is that I can compile a source file to bytecodes, execute bytecodes, or do both at once:
I made a couple of minor tweaks in the port, because I wanted extra facilities. Rather than implement an opcode "STRING_LENGTH" I copied the idea of traps - so a program can call-back to the interpreter to run some operations:
int 0x00 -> Set register 0 with the length of the string in register 0.
int 0x01 -> Set register 0 with the contents of reading a string from the user
etc.
This notion of traps should allow complex operations to be implemented easily, in golang. I don't think I have the patience to do too much more, but it stands as a simple example of a "compiler" or an interpreter.
I think this program is the longest I've written. Remember how verbose assembly language is?
Otherwise: Helsinki Pride happened, Oiva learned to say his name (maybe?), and I finished reading all the James Bond novels (which were very different to the films, and have aged badly on the whole).
Tags: golang, simple-vm
|
27 July 2018 13:01
For the past couple of days I've gone back over my golang projects, and updated each of them to have zero golint/govet warnings.
Nothing significant has changed, but it's nice to be cleaner.
I did publish a new project, which is a webmail client implemented in golang. Using it you can view the contents of a remote IMAP server in your browser:
- View folders.
- View messages.
- View attachments
- etc.
The (huge) omission is the ability to reply to messages, compose new mails, or forward/delete messages. Still as a "read only webmail" it does the job.
Not a bad hack, but I do have the problem that my own mailserver presents ~/Maildir over IMAP and I have ~1000 folders. Retrieving that list of folders is near-instant - but retrieving that list of folders and the unread-mail count of each folder takes over a minute.
For the moment I've just not handled folders-with-new-mail specially, but it is a glaring usability hole. There are solutions, the two most obvious:
- Use an AJAX call to get/update the unread-counts in the background.
- Causes regressions as soon as you navigate to a new page though.
- Have some kind of open proxy-process to maintain state and avoid accessing IMAP directly.
- That complicates the design, but would allow "instant" fetches of "stuff".
Anyway check it out if you like. Bug reports welcome.
Tags: golang, webmail
|
4 September 2018 15:01
I have written a lot of software which I deploy upon my own systems. Typically I deploy these things via puppet, but some things are more ad-hoc. For the ad-hoc deployments I tend to rely upon ssh to deploy them.
I have a bunch of shell-scripts, each called .deploy, which carries out the necessary steps. Here is an example script which deploys my puppet-summary service upon a host:
#!/bin/sh
HOST=master.steve.org.uk
RELEASE=1.2
# download
ssh -t ${HOST} "wget --quiet -O /srv/puppet-summary/puppet-summary-linux-amd64-${RELEASE} https://github.com/skx/puppet-summary/releases/download/release-${RELEASE}/puppet-summary-linux-amd64"
# symlink
ssh -t ${HOST} "ln -sf /srv/puppet-summary/puppet-summary-linux-amd64-${RELEASE} /srv/puppet-summary/puppet-summary"
# make executable
ssh -t ${HOST} "chmod 755 /srv/puppet-summary/puppet-summary*"
# restart
ssh -t ${HOST} "systemctl restart puppet-summary.service"
As you can see this script is very obvious:
- Download a binary release from a github-page.
- Symlinks a fixed name to point to this numbered-release.
- Ensures the download is executable.
- Then restarts a service.
This whole process is pretty painless, but it assumes prior-setup. For example it assumes that the systemd unit-file is in-place, and any corresponding users, directories, and configuration-files.
I wanted to replace it with something simple to understand, and that replacement system had to have the ability to do two things:
- Copy a file from my local system to the remote host.
- Run a command upon the remote host.
That would let me have a local tree of configuration-files, and allow them to be uploaded, and then carry out similar steps to the example above.
Obviously the simplest way to go would be to use fabric, ansible, salt, or even puppet. That would be too easy.
So I wondered could I write a script like this:
# Copy the service-file into place
CopyFile puppet-summary.service /lib/systemd/system/puppet-summary.service
IfChanged "systemctl daemon-reload"
IfChanged "systemctl enable puppet-summary.service"
# Fetch the binary
Run "wget --quiet -O /srv/puppet-summary/puppet-summary-linux-amd64-${RELEASE} https://github.com/skx/puppet-summary/releases/download/release-${RELEASE}/puppet-summary-linux-amd64"
# Run the rest here ..
Run "ln -sf .."
..
Run "systemctl restart puppet-summary.service"
Turns out that connecting to a remote-host, via SSH, and using that single connection to either upload/download files or run commands is very simple in golang. So I'm quite placed with that.
I've only added three primitives, and the ability to set/expand variables:
CopyFile [local-file-name] [remote-file-name]
- This sets a flag if the remote file was missing, or the contents changed.
IfChanged
- Run a command only if the file-copy flag was set.
Run
- Run a command. Unconditionally.
I suspect if I needed much more than that I should use something else. But having dealt with Ansible deployments in the past I'm very glad I didn't use that.
(It makes a lot of sense to have the repositories for deploying application A inside the repository of project A. Another reason to not use ansible, etc. Though I guess fabric would work well with that, as recipes are typically contained in ./fabfile.py. Of course .. python.)
Tags: deployr, golang, releases
|
29 September 2018 19:19
I've updated my fork of the monkey programming language to allow object-based method calls.
That's allowed me to move some of my "standard-library" code into Monkey, and out of Go which is neat. This is a simple example:
//
// Reverse a string,
//
function string.reverse() {
let r= "";
let l = len(self);
for( l > 0 ) {
r += self[l-1];
l--;
}
return r;
}
Usage is the obvious:
puts( "Steve".reverse() );
Or:
let s = "Input";
s = s.reverse();
puts( s + "\n" );
Most of the pain here was updating the parser to recognize that "." meant a method-call was happening, once that was done it was otherwise only a matter of passing the implicit self object to the appropriate functions.
This work was done in a couple of 30-60 minute chunks. I find that I'm only really able to commit to that amount of work these days, so I've started to pull back from other projects.
Oiva is now 21 months old and he sucks up all my time & energy. I can't complain, but equally I can't really start concentrating on longer-projects even when he's gone to sleep.
And that concludes my news for the day.
Goodnight dune..
Tags: golang, monkey
|
20 October 2018 12:01
So back in June I challenged myself to write a BASIC interpreter in a weekend. The next time I mentioned it was to admit defeat. I didn't really explain in any detail, because I thought I'd wait a few days and try again and I was distracted at the time I wrote my post.
As it happened that was over four months ago, so clearly it didn't work out. The reason for this was because I was getting too bogged down in the wrong kind of details. I'd got my heart set on doing this the "modern" way:
- Write a lexer to spit the input into tokens
LINE-NUMBER:10, PRINT, "Hello, World"
- Then I'd take those tokens and form an abstract syntax tree.
- Finally I'd walk the tree evaluating as I went.
The problem is that almost immediately I ran into problems, my naive approach didn't have a good solution for identifying line-numbers. So I was too paralysed to proceed much further.
I sidestepped the initial problem and figured maybe I should just have a series of tokens, somehow, which would be keyed off line-number. Obviously when you're interpreting "traditional" BASIC you need to care about lines, and treat them as important because you need to handle fun-things like this:
10 PRINT "STEVE ROCKS"
20 GOTO 10
Anyway I'd parse each line, assuming only a single statement upon a line (ha!) you can divide it into:
- Number - i.e. line-number.
- Statement.
- Newline to terminate.
Then you could have:
code{blah} ..
code[10] = "PRINT STEVE ROCKS"
code[20] = "GOTO 10"
Obviously you spot the problem there, if you think it through. Anyway. I've been thinking about it off and on since then, and the end result is that for the past two evenings I've been mostly writing a BASIC interpreter, in golang, in 20-30 minute chunks.
The way it works is as you'd expect (don't make me laugh ,bitterly):
- Parse the input into tokens.
- Store those as an array.
- Interpet each token.
- No AST
- No complicated structures.
- Your program is literally an array of tokens.
I cheated, horribly, in parsing line-numbers which turned out to be exactly the right thing to do. The output of my naive lexer was:
INT:10, PRINT, STRING:"Hello World", NEWLINE, INT:20, GOTO, INT:10
Guess what? If you (secretly) prefix a newline to the program you're given you can identify line-numbers just by keeping track of your previous token in the lexer. A line-number is any number that follows a newline. You don't even have to care if they sequential. (Hrm. Bug-report?)
Once you have an array of tokens it becomes almost insanely easy to process the stream and run your interpreter:
program[] = { LINE_NUMBER:10, PRINT, "Hello", NEWLINE, LINE_NUMBER:20 ..}
let offset := 0
for( offset < len(program) ) {
token = program[offset]
if ( token == GOTO ) { handle_goto() ; }
if ( token == PRINT ) { handle_print() ; }
.. handlers for every other statement
offset++
}
Make offset a global. And suddenly GOTO 10 becomes:
- Scan the array, again, looking for "LINE_NUMBER:10".
- Set
offset to that index.
Magically it all just works. Add a stack, and GOSUB/RETURN are handled with ease too by pushing/popping the offset to it.
In fact even the FOR-loop is handled in only a few lines of code - most of the magic happening in the handler for the "NEXT" statement (because that's the part that needs to decide if it needs to jump-back to the body of the loop, or continue running.
OK this is a basic-BASIC as it is missing primtives (CHR(), LEN,etc) and it only cares about integers. But the code is wonderfully simple to understand, and the test-case coverage is pretty high.
I'll leave with an example:
10 REM This is a program
00 REM
01 REM This program should produce 126 * 126 * 10
02 REM = 158760
03 REM
05 GOSUB 100
10 FOR i = 0 TO 126
20 FOR j = 0 TO 126 STEP 1
30 FOR k = 0 TO 10
40 LET a = i * j * k
50 NEXT k
60 NEXT j
70 NEXT i
75 PRINT a, "\n"
80 END
100 PRINT "Hello, I'm multiplying your integers"
110 RETURN
Loops indented for clarity. Tokens in upper-case only for retro-nostalgia.
Find it here, if you care:
I had fun. Worth it.
I even "wrote" a "game":
Tags: basic, golang, interpreter
|
23 October 2018 12:01
So my previous post described a BASIC interpreter I'd written.
Before the previous release I decided to ensure that it was easy to embed, and that it was possible to extend the BASIC environment such that it could call functions implemented in golang.
One of the first things that came to mind was to allow a BASIC script to plot pixels in a PNG. So I made that possible by adding "PLOT x,y" and "SAVE" primitives.
Taking that step further I then wrote a HTTP-server which would allow you to enter a BASIC program and view the image it created. It's a little cute at least.
Install it from source, or fetch a binary if you prefer, via:
$ go get -u github.com/skx/gobasic/goserver
Then launch it and point your browser at http://localhost:8080, and you'll be presented with something like this:
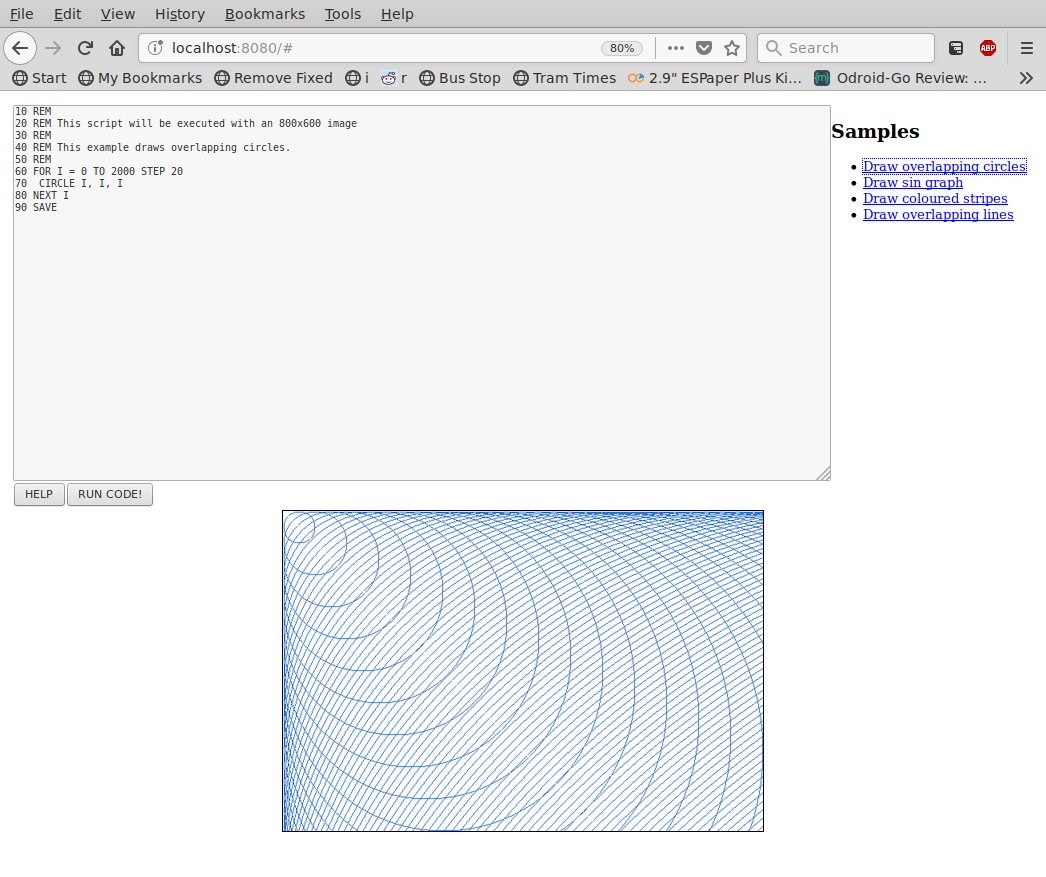
Fun times.
Tags: basic, golang, interpreter
|
31 January 2019 15:01
I've spent some time in the recent past working with interpreters, and writing a BASIC interpreter, but one thing I'd not done is write a compiler.
Once upon a time I worked for a compiler-company, but I wasn't involved with the actual coding at that time. Instead I worked on other projects, and did a minor amount of system-administration.
There are enough toy-languages that it didn't seem worthwhile to write a compiler for yet another one. At the same time writing a compiler for a full-language would get bogged down in a lot of noise.
So I decided to simplify things: I would write a compiler for "maths". Something that would take an expression and output assembly-language, which could then be compiled.
The end result is this simple compiler:
Initially I wrote something that would parse expressions such as 3 + 4 * 5 and output an abstract-syntax-tree. I walked the tree and started writing logic to pick registers, and similar. It all seemed like more of a grind than a useful exercise - and considering how ludicrous compiling simple expressions to assembly language already was it seemed particularly silly.
So once again I simplified, deciding to accept only a simple "reverse-polish-like" expression, and outputing the assembly for that almost directly.
Assume you want to calculate "((3 * 5) +2)" you'd feed my compiler:
3 5 * 2 +
To compile that we first load the initial state 3, then we walk the rest of the program always applying an operation with an operand:
- Store
3
5 * -> multiply by 5.2 + -> add 2.- ..
This approach is trivial to parse, and trivial to output the assembly-language for: Pick a register and load your starting value, then just make sure all your operations apply to that particular register. (In the case of Intel assembly it made sense to store the starting value in EAX, and work with that).
A simple program would then produce a correspondingly simple output. Given 1 1 + we'd expect this output:
.intel_syntax noprefix
.global main
.data
result: .asciz "Result %d\n"
main:
mov rax, 1
add rax, 1
lea rdi,result
mov rsi, rax
xor rax, rax
call printf
xor rax, rax
ret
With that output you can assemble the program, and run it:
$ gcc -static -o program program.s
$ ./program
Result 2
I wrote some logic to allow calculating powers too, so you can output 2 ^ 8, etc. That's just implemented the naive-way, where you have a small loop and multiply the contents of EAX by itself the appropriate number of times. Modulus is similarly simple to calculate.
Adding support for named variables, and other things, wouldn't be too hard. But it would involve register-allocation and similar complexity. Perhaps that's something I need to flirt with, to make the learning process complete, but to be honest I can't be bothered.
Anyway check it out, if you like super-fast maths. My benchmark?
$ time perl -e 'print 2 ** 8 . "\n"'
256
real 0m0.006s
user 0m0.005s
sys 0m0.000s
vs.
$ math-compiler -compile '2 8 ^'
$ time ./a.out
Result 256
real 0m0.001s
user 0m0.001s
sys 0m0.000s
Wow. Many wow. Much speed. All your base-two are belong to us.
Tags: compilers, github, golang, math, toy
|
16 February 2019 18:26
The simple math-compiler I introduced in my previous post has had a bit of an overhaul, so that now it is fully RPN-based.
Originally the input was RPN-like, now it is RPN for real. It handles error-detection at run-time, and generates a cleaner assembly-language output:
In other news I bought a new watch, which was a fun way to spend some time.
I love mechanical watches, clocks, and devices such as steam-engines. While watches are full of tiny and intricate parts I like the pretence that you can see how they work, and understand them. Steam engines are seductive because their operation is similar; you can almost look at them and understand how they work.
I've got a small collection of watches at the moment, ranging from €100-€2000 in price, these are universally skeleton-watches, or open-heart watches.
My recent purchase is something different. I was looking at used Rolexs, and found some from 1970s. That made me suddenly wonder what had been made the same year as I was born. So I started searching for vintage watches, which had been manufactured in 1976. In the end I found a nice Soviet Union piece, made by Raketa. I can't prove that this specific model was actually manufactured that year, but I'll keep up the pretence. If it is +/- 10 years that's probably close enough.
My personal dream-watch is the Rolex Oyster (I like to avoid complications). The Oyster is beautiful, and I can afford it. But even with insurance I'd feel too paranoid leaving the house with that much money on my wrist. No doubt I'll find a used one, for half that price, sometime. I'm not in a hurry.
(In a horological-sense a "complication" is something above/beyond the regular display of time. So showing the day, the date, or phase of the moon would each be complications.)
Tags: compilers, github, golang, math, watches
|
26 February 2019 12:01
Recently I heared that travis-CI had been
bought out, and later that
they'd started to fire their staff.
I've used Travis-CI for a few years now, via github, to automatically build
binaries for releases, and to run tests.
Since I was recently invited to try the Github Actions beta I figured it was time to experiment.
Github actions allow you to trigger "stuff" on "actions". Actions are things
like commits being pushed to your repository, new releases appearing, and so on. "Stuff" is basically "launch a specific docker container".
The specified docker container has a copy of your project repository cloned into it, and you can operate upon it pretty freely.
I created two actions (which basically means I authored two Dockerfiles), and setup the meta-information, so that now I can do what I used to do with travis easily:
- github-action-tester
- Allows tests to be run whenever a new commit is pushed to your repository.
- Or whenever a pull-request is submitted, or updated.
- github-actions-publish-binaries
- If you create a new release in the github UI your project is built, and the specified binaries are attached to the release.
Configuring these in the repository is very simple, you have to define a workflow at .github/main.workflow, and my projects tend to look very similar:
# pushes trigger the testsuite
workflow "Push Event" {
on = "push"
resolves = ["Test"]
}
# pull-requests trigger the testsuite
workflow "Pull Request" {
on = "pull_request"
resolves = ["Test"]
}
# releases trigger new binary artifacts
workflow "Handle Release" {
on = "release"
resolves = ["Upload"]
}
##
## The actions
##
##
## Run the test-cases, via .github/run-tests.sh
##
action "Test" {
uses = "skx/github-action-tester@master"
}
##
## Build the binaries, via .github/build, then upload them.
##
action "Upload" {
uses = "skx/github-action-publish-binaries@master"
args = "math-compiler-*"
secrets = ["GITHUB_TOKEN"]
}
In order to make the actions generic they both execute a shell-script inside your repository. For example the action to run the tests just executes
That way you can write the tests that make sense. For example a golang application would probably run go test ..., but a C-based system might run make test.
Similarly the release-making action runs .github/build, and assumes that will produce your binaries, which are then uploaded.
The upload-action requires the use of a secret, but it seems to be handled by
magic - I didn't create one. I suspect GITHUB_TOKEN is a magic-secret which
is generated on-demand.
Anyway I updated a few projects, and you can see their configuration by looking at .github within the repository:
All in all it was worth the few hours I spent on it, and now I no longer use Travis-CI. The cost? I guess now I'm tied to github some more...
Tags: automation, github, golang, travis
|
7 April 2019 12:01
Recently I've been dealing with a lot of PHP code, and coders. I'm still not a huge fan of the language, but at the same time modern PHP is a world apart from legacy PHP which I dismissed 10ish years ago.
I've noticed a lot of the coders have had a good habit of documenting their code, but also consistently failing to keep class-names up to date. For example this code:
<?php
/**
* Class Bar
*
* Comments go here ..
*/
class Foo
{
..
The rest of the file? Almost certainly correct, but that initial header contained a reference to the class Bar even though the implementation presented Foo.
I found a bunch of PHP linters which handle formatting, and coding-style checks, but nothing to address this specific problem. So I wrote a quick hack:
- Parse PHP files.
- Look for "
/*".
- Look for "
*/".
- Look for "
class".
- Treat everything else as a token, except for whitespace which we just silently discard.
Once you have a stream of such tokens you can detect this:
- Found the start of a comment?
- Clear the contents of any previously saved comment, in
lastComment.
- Append each subsequent token to "
lastComment" until you hit EOF, or the end of a comment token.
- Found a class token?
- Look at the contents of the
lastComment variable and see if it contains "class", after all the class might not have documentation that refers to any class.
- If there is "class xxx" mentioned check it matches the current class name.
There were some initial false-positives when I had to handle cases like this:
throw new \Exception("class not found");
(Here my naive handling would decide we'd found a class called not.)
Anyway the end result was stable and detected about 150 offenses in the 2000 file codebase I'm looking at.
Good result. Next step was integrating that into the CI system.
And that concludes my recent PHP adventures, using go to help ;)
(Code isn't public; I suspect you could rewrite it in an hour. I also suspect I was over-engineering and a perl script using regexp would do the job just as well..)
Tags: golang, php
|
17 September 2019 21:50
So recently I've been on-call, expected to react to events around the clock. Of course to make it more of a challenge alerts are usually raised via messages to a specific channel in slack which come from a variety of sources. Let's pretend I'm all retro/hip and I'm using IRC instead.
Knowing what I'm like I knew there was essentially zero chance a single beep on my phone, from the slack/irc app, would wake me up. So I spent a couple of hours writing a simple bot:
- Connect to the server.
- Listen for messages.
- When an alert is posted in the channel:
- Trigger a voice-call via the twilio API.
That actually worked out really, really, really well. Twilio would initiate a call to my mobile which absolutely would, could, and did wake me up. I did discover a problem pretty quickly though; too many phone-calls!
Imagine something is broken. Imagine a notice goes to your channel, and then people start replying to it:
Some Bot: Help! Stuff is broken! I'm on Fire!! :fire: :hot: :boom:
Colleague Bob: Is this real?
Colleague Ann: Can you poke Chris?
Colleage Chris: Oh dears, woe is me.
The first night I was on call I got a phone call. Then another. Then another. Even I replied to the thread/chat to say "Yeah I'm on it". So the next step was to refine my alerting:
- If there is a message in the channel
- Which is not from Bob
- Which is not from Steve
- Which is not from Ann
- Which is not from Chris
- Which doesn't contain the text "common false-positive"
- Which doesn't contain the text "backup completed"
- Then make a phone-call.
Of course the next problem was predictable enough, so the rules got refined:
- If the time is between 7PM and 7AM raise the alert.
- Unless it is the weekend in which case we alert regardless of the time of day.
So I had a growing set of rules. All encoded in my goloang notification application. I moved some of them to JSON (specificially a list of users/messages to ignore) but things like the time of day were harder to move.
I figured I shouldn't be hardwiring these things. So last night put together a simple filter-library, an evaluation engine, in golang to handle them. Now I can load a script and filter things out much more dynamically. For example assume I have the following struct:
type Message struct {
Author string
Channel string
Message string
..
}
And an instance of that struct named message, I can run a user-written script against that object:
// Create a new eval-filter
eval, er := evalfilter.New( "script goes here ..." )
// Run it against the "message" object
out, err := eval.Run( message )
The logic of reacting now goes inside that script, which is hopefully easy to read - but more importantly can be edited without recompiling the application:
//
// This is a filter script:
//
// return false means "do nothing".
// return true means initiate a phone-call.
//
//
// Ignore messages on channels that we don't care about
//
if ( Channel !~ "_alerts" ) { return false; }
//
// Ignore messages from humans who might otherwise write in our channels
// of interest.
//
if ( Sender == "USER1" ) { return false; } // Steve
if ( Sender == "USER2" ) { return true; } // Ann
if ( Sender == "USER3" ) { return false; } // Bob
//
// Is it a weekend? Always alert.
//
if ( IsWeekend() ) { return true ; }
//
// OK so it is not a weekend.
//
// We only alert if 7pm-7am
//
// The WorkingHours() function returns `true` during working hours.
//
if ( WorkingHours() ) { return false ; }
//
// OK by this point we should raise a call:
//
// * The message was NOT from a colleague we've filtered out.
// * The message is upon a channel with an `_alerts` suffix.
// * It is not currently during working hours.
// * And we already handled weekends by raising calls above.
//
return true ;
If the script returns true I initiate a phone-call. If the script returns false we ignore the message/event.
The alerting script itself is trivial, and probably non-portable, but the filtering engine is pretty neat. I can see a few more uses for it, even without it having nested blocks and a real grammar. So take a look, if you like:
Tags: evalfilter, golang, hack, slack, twilio
|
8 October 2019 18:00
When this post becomes public I'll have successfully redeployed my blog!
My blog originally started in 2005 as a Wordpress installation, at some
point I used Mephisto, and then I wrote my own solution.
My project was pretty cool; I'd parse a directory of text-files, one
file for each post, and insert them into an SQLite database. From there
I'd initiate a series of plugins, each one to generate something specific:
- One plugin would output an archive page.
- Another would generate a tag cloud.
- Yet another would generate the actual search-results for a particular month/year, or tag-name.
All in all the solution was flexible and it wasn't too slow because
finding posts via the SQLite database was pretty good.
Anyway I've come to realize that freedom and architecture was overkill.
I don't need to do fancy presentation, I don't need a loosely-coupled
set of plugins.
So now I have a simpler solution which uses my existing template, uses
my existing posts - with only a few cleanups - and generates the site
from scratch, including all the comments, in less than 2 seconds.
After running make clean a complete rebuild via make upload (which
deploys the generated site to the remote host via rsync) takes 6 seconds.
I've lost the ability to be flexible in some areas, but I've gained all
the speed. The old project took somewhere between 20-60 seconds to
build, depending on what had changed.
In terms of simplifying my life I've dropped the remote installation of
a site-search which means I can now host this site on a static site with
only a single handler to receive any post-comments. (I was 50/50 on
keeping comments. I didn't want to lose those I'd already received, and
I do often find valuable and interesting contributions from readers, but
being 100% static had its appeal too. I guess they stay for the next
few years!)
Tags: chronicle, golang
|
18 November 2019 19:45
I've recently spent some time working with a simple scripting language. Today I spent parts of the day trying to make it faster. As a broad overview we'll be considering this example script:
if ( 1 + 2 * 3 == 7 ) { return true; }
return false;
This gets compiled into a simple set of bytecode instructions, which can refer to a small collection of constants - which are identified by offset/ID:
000000 OpConstant 0 // load constant: &{1}
000003 OpConstant 1 // load constant: &{2}
000006 OpConstant 2 // load constant: &{3}
000009 OpMul
000010 OpAdd
000011 OpConstant 3 // load constant: &{7}
000014 OpEqual
000015 OpJumpIfFalse 20
000018 OpTrue
000019 OpReturn
000020 OpFalse
000021 OpReturn
Constants:
000000 Type:INTEGER Value:1
000001 Type:INTEGER Value:2
000002 Type:INTEGER Value:3
000003 Type:INTEGER Value:7
The OpConstant instruction means to load the value with the given ID from the constant pool and place it onto the top of the stack. The multiplication and addition operations both pop values from the stack, apply the appropriate operation and push the result back. All standard stuff.
Of course these constants are constant so it seemed obvious to handle the case of integers as a special case. Rather than storing them in the constant-pool, where booleans, strings, etc live, we just store them inline. That meant our program would look like this:
000000 OpPush 1
000003 OpPush 2
000006 OpPush 3
000009 OpMul
000010 OpAdd
...
At this point the magic begins: we can scan the program from start to finish. Every time we find "OpPush", "OpPush", then "Maths" we can rewrite the program to contain the appropriate result already. So this concrete fragment:
OpPush 2
OpPush 3
OpMul
is now replaced by:
OpPush 6
OpNop ; previous opconstant
OpNop ; previous arg1
OpNop ; previous arg2
OpNop ; previous OpMul
Repeating the process, and applying the same transformation to our comparision operation we now have the updated bytecode of:
000000 OpNop
000001 OpNop
000002 OpNop
000003 OpNop
000004 OpNop
000005 OpNop
000006 OpNop
000007 OpNop
000008 OpNop
000009 OpNop
000010 OpNop
000011 OpNop
000012 OpNop
000013 OpNop
000014 OpTrue
000015 OpJumpIfFalse 20
000018 OpTrue
000019 OpReturn
000020 OpFalse
000021 OpReturn
The OpTrue instruction pushes a "true" value to the stack, while the OpJumpIfFalse only jumps to the given program offset if the value popped off the stack is non-true. So we can remove those two instructions.
Our complete program is now:
000000 OpNop
000001 OpNop
000002 OpNop
000003 OpNop
000004 OpNop
000005 OpNop
000006 OpNop
000007 OpNop
000008 OpNop
000009 OpNop
000010 OpNop
000011 OpNop
000012 OpNop
000013 OpNop
000014 OpNop
000015 OpNop
000018 OpTrue
000019 OpReturn
000020 OpFalse
000021 OpReturn
There are two remaining obvious steps:
- Remove all the OpNop instructions.
- Recognize the case that there are zero jumps in the generated bytecode.
- In that case we can stop processing code once we hit the first OpReturn
With that change made our input program:
if ( 1 + 2 * 3 == 7 ) { return true; } return false;
Now becomes this compiled bytecode:
000000 OpTrue
000001 OpReturn
Which now runs a lot faster than it did in the past. Of course this is completely artificial, but it was a fun process to work through regardless.
Tags: bytecode, evalfilter, golang, optimization
|
8 January 2020 19:19
Once upon a time I wrote an email client, in a combination of C++ and Lua.
Later I realized it was flawed, and because I hadn't realized that writing email clients is hard I decided to write it anew (again in C++ and Lua).
Nowadays I do realize how hard writing email clients is, so I'm not going to do that again. But still .. but still ..
I was doing some mail-searching recently and realized I wanted to write something that processed all the messages in a Maildir folder. Imagine I wanted to run:
message-dump ~/Maildir/people-foo/ ~/Maildir/people-bar/ \
--format '${flags} ${filename} ${subject}'
As this required access to (arbitrary) headers I had to read, parse, and process each message. It was slow, but it wasn't that slow. The second time I ran it, even after adjusting the format-string, it was nice and fast because buffer-caches rock.
Anyway after that I wanted to write a script to dump the list of folders (because I store them recursively so ls -1 ~/Maildir wasn't enough):
maildir-dump --format '${unread}/${total} ${path}'
I guess you can see where this is going now! If you have the following three primitives, you have a mail-client (albeit read-only)
- List "folders"
- List "messages"
- List a single message.
So I hacked up a simple client that would have a sub-command for each one of these tasks. I figured somebody else could actually use that, be a little retro, be a little cool, pretend they were using MH. Of course I'd have to write something horrid as a bash-script to prove it worked - probably using dialog to drive it.
And then I got interested. The end result is a single golang binary that will either:
- List maildirs, with a cute format string.
- List messages, with a cute format string.
- List a single message, decoding the RFC2047 headers, showing
text/plain, etc.
- AND ALSO USE ITSELF TO PROVIDE A GUI
And now I wonder, am I crazy? Is writing an email client hard? I can't remember
- Current user-interface:
- Current source code:
Probably best to forget the GUI exists. Probably best to keep it a couple of standalone sub-commands for "scripting email stuff".
But still .. but still ..
Tags: email, golang, maildir, maildir-utils
|
16 January 2020 19:19
myrepos is an excellent tool for applying git operations to multiple repositories, and I use it extensively.
Given a configuration file like this:
..
[github.com/skx/asql]
checkout = git clone [email protected]:skx/asql.git
[github.com/skx/bookmarks.public]
checkout = git clone [email protected]:skx/bookmarks.public.git
[github.com/skx/Buffalo-220-NAS]
checkout = git clone [email protected]:skx/Buffalo-220-NAS.git
[github.com/skx/calibre-plugins]
checkout = git clone [email protected]:skx/calibre-plugins.git
...
You can clone all the repositories with one command:
mr -j5 --config .mrconfig.github checkout
Then pull/update them them easily:
mr -j5 --config .mrconfig.github update
It works with git repositories, mercurial, and more. (The -j5 argument means to run five jobs in parallel. Much speed, many fast. Big wow.)
I wrote a simple golang utility to use the github API to generate a suitable configuration including:
- All your personal repositories.
- All the repositories which belong to organizations you're a member of.
Currently it only supports github, but I'll update to include self-hosted and API-compatible services such as gitbucket. Is there any interest in such a tool? Or have you all written your own already?
(I have the feeling I've written this tool in Perl, Ruby, and even using curl a time or two already. This time I'll do it properly and publish it to save effort next time!)
Tags: github, golang, mr, myrepos
|
17 January 2020 19:19
myrepos is an excellent tool for applying git operations to multiple repositories, and I use it extensively.
I've written several scripts to dump remote repository-lists into a suitable configuration format, and hopefully I've done that for the last time.
github2mr correctly handles:
- Exporting projects from Github.com
- Exporting projects from (self-hosted installations of) Github Enterprise.
- Exporting projects from (self-hosted installations of) Gitbucket.
If it can handle Gogs, Gitea, etc, then I'd love to know, otherwise patches are equally welcome!
Tags: github, github2mr, golang, mr, myrepos
|
24 January 2020 12:20
After 10+ years I'm in the process of retiring my mail-host. In the future I'll no longer be running exim4/dovecot/similar, and handling my own mail. Instead it'll all go to a (paid) Google account.
It feels like the end of an era, as it means a lot of my daily life will not be spent inside a single host no longer will I run:
ssh [email protected]
I'm still within my Gsuite trial, but I've mostly finished importing my vast mail archive, via mbsync.
The only outstanding thing I need is some scripting for the mail. Since my mail has been self-hosted I've evolved a large and complex procmail configuration file which sorted incoming messages into Maildir folders.
Having a quick look around last night I couldn't find anything similar for the brave new world of Google Mail. So I hacked up a quick script which will automatically add labels to new messages that don't have any.
Finding messages which are new/unread and which don't have labels is a matter of searching for:
is:unread -has:userlabels
From there adding labels is pretty simple, if you decide what you want. For the moment I'm keeping it simple:
- If a message comes from
"Bob Smith" <[email protected]>
- I add the label "
bob.smith".
- I add the label "
example.com".
Both labels will be created if they don't already exist, and the actual coding part was pretty simple. To be more complex/flexible I would probably need to integrate a scripting language (oh, I have one of those), and let the user decide what to do for each message.
The biggest annoyance is setting up the Google project, and all the OAUTH magic. I've documented briefly what I did but I don't actually know if anybody else could run the damn thing - there's just too much "magic" involved in these APIs.
Anyway procmail-lite for gmail. Job done.
Tags: dovecot, exim, gmail, golang, gsuite, maildir, procmail
|
14 April 2020 09:00
In a previous job I wrote some simple utilities which were helpful for continuous-integration pipelines. Most of these were very very simple, for example:
- Find all
*.json files, and validate them.
- Find all
*.yaml files, and validate them.
- Run all the tests in a given directory, execute them one by one.
- But stop if any single test failed.
run-parts does this on Debian GNU/Linux systems, but on CentOS there is no -exit-on-error flag.- Which is the sole reason I had to re-implement that tool. Sigh.
- Parse PHP-files and look for comments that were bogus.
Each of these simple tools were run of the mill shell-scripts, or simple binaries. I've been putting together a simple deployable tool which lets you run them easily, so here it is:
The idea is that you install the tool, then run the commands by specify the appropriate sub-command:
sysbox validate-yaml [path/to/find/files/beneath]
Of course if you symlink validate-yaml to sysbox you don't need to prefix with the name - so this is just like busybox in this regard.
Might be interesting to some.
Tags: ci, golang, syadmin-tools, utility
|
29 April 2020 14:00
For the foreseeable future I'm working for myself, as a contractor, here in sunny Helsinki, Finland.
My existing contract only requires me to work 1.5-2.0 days a week, meaning my week looks something like this:
- Monday & Tuesday
- Wednesday - Friday
- I act as a stay-at-home dad.
It does mean that I'm available for work Wednesday-Friday though, in the event I can find projects to work upon, or companies who would be willing to accept my invoices.
I think of myself as a sysadmin, but I know all about pipelines, automation, system administration, and coding in C, C++, Perl, Ruby, Golang, Lua, etc.
On the off-chance anybody reading this has a need for small projects, services, daemons, or APIs to be implemented then don't hesitate to get in touch.
I did manage to fill a few days over the past few weeks completing an online course from Helsinki Open University, Devops with Docker, it is possible I'll find some more courses to complete in the future. (There is an upcoming course Devops with Kubernetes which I'll definitely complete.)
Tags: devops, docker, employment, golang, helsinki, open university, sysadmin
|
17 May 2020 15:00
I started work on sysbox again recently, adding a couple of simple utilities. (The whole project is a small collection of utilities, distributed as a single binary to ease installation.)
Imagine you want to run a command for every line of STDIN, here's a good example:
$ cat input | sysbox exec-stdin "youtube-dl {}"
Here you see for every (non-empty) line of input read from STDIN the command "youtube-dl" has been executed. "{}" gets expanded to the complete line read. You can also access individual fields, kinda like awk.
(Yes youtube-dl can read a list of URLs from a file, this is an example!)
Another example, run groups for every local user:
$ cat /etc/passwd | sysbox exec-stdin --split=: groups {1}
Here you see we have split the input-lines read from STDIN by the : character, instead of by whitespace, and we've accessed the first field via "{1}". This is certainly easier for scripting than using a bash loop.
On the topic of bash; command-completion for each subcommand, and their arguments, is now present:
$ source <(sysbox bash-completion)
And I've added a text-based UI for selecting files. You can also execute a command, against the selected file:
$ sysbox choose-file -exec "xine {}" /srv/tv
This is what that looks like:
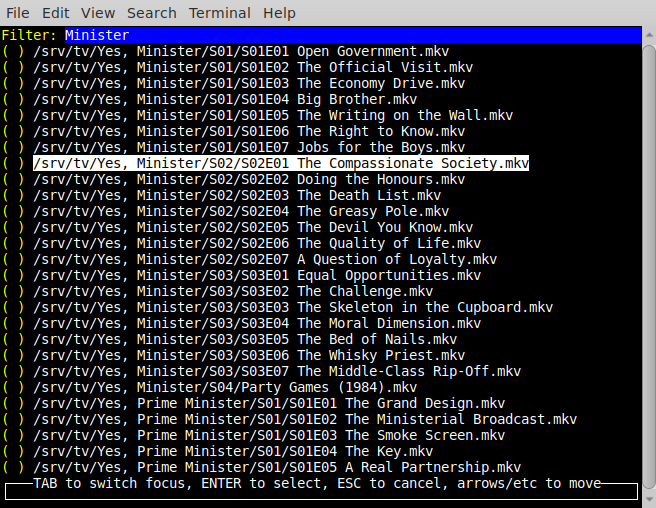
You'll see:
- A text-box for filtering the list.
- A list which can be scrolled up/down/etc.
- A brief bit of help information in the footer.
As well as choosing files, you can also select from lines read via STDIN, and you can filter the command in the same way as before. (i.e. "{}" is the selected item.)
Other commands received updates, so the calculator now allows storing results in variables:
$ sysbox calc
calc> let a = 3
3
calc> a / 9 * 3
1
calc> 1 + 2 * a
7
calc> 1.2 + 3.4
4.600000
Tags: golang, scripting, sysadmin, sysbox
|
14 June 2020 19:00
So last night I had the idea that it might be fun to write a Brainfuck compiler, to convert BF programs into assembly language, where they'd run nice and quickly.
I figured I could allocate a day to do the work, and it would be a pleasant distraction on a Sunday afternoon. As it happened it only took me three hours from start to finish.
There are only a few instructions involved in brainfuck:
>
- increment the data pointer (to point to the next cell to the right).
<
- decrement the data pointer (to point to the next cell to the left).
+
- increment (increase by one) the byte at the data pointer.
-
- decrement (decrease by one) the byte at the data pointer.
.
- output the byte at the data pointer.
,
- accept one byte of input, storing its value in the byte at the data pointer.
[
- if the byte at the data pointer is zero, then instead of moving the instruction pointer forward to the next command, jump it forward to the command after the matching
] command.
]
- if the byte at the data pointer is nonzero, then instead of moving the instruction pointer forward to the next command, jump it back to the command after the matching
[ command.
The Wikipedia link early shows how you can convert cleanly to a C implementation, so my first version just did that:
- Read a BF program.
- Convert to a temporary C-source file.
- Compile with
gcc.
- End result you have an executable which you can run.
The second step was just as simple:
- Read a BF program.
- Convert to a temporary assembly language file.
- Compile with
nasm, link with ld.
- End result you have an executable which you can run.
The following program produces the string "Hello World!" to the console:
++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.
My C-compiler converted that to the program:
extern int putchar(int);
extern char getchar();
char array[30000];
int idx = 0;
int main (int arc, char *argv[]) {
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
while (array[idx]) {
idx++;
array[idx]++;
array[idx]++;
array[idx]++;
array[idx]++;
while (array[idx]) {
idx++;
array[idx]++;
array[idx]++;
idx++;
array[idx]++;
array[idx]++;
array[idx]++;
..
..
The assembly language version is even longer:
global _start
section .text
_start:
mov r8, stack
add byte [r8], 8
label_loop_8:
cmp byte [r8], 0
je close_loop_8
add r8, 1
add byte [r8], 4
label_loop_14:
cmp byte [r8], 0
je close_loop_14
add r8, 1
add byte [r8], 2
add r8, 1
add byte [r8], 3
add r8, 1
add byte [r8], 3
add r8, 1
add byte [r8], 1
sub r8, 4
sub byte [r8], 1
jmp label_loop_14
close_loop_14:
add r8, 1
add byte [r8], 1
..
mov rax, 60
mov rdi, 0
syscall
section .bss
stack: resb 300000
Annoyingly the assembly language version ran slower than the C-version, which I was sneakily compiling with "gcc -O3 .." to ensure it was optimized.
The first thing that I did was to convert it to fold adjacent instructions. Instead of generating separate increment instructions for ">>>" I instead started to generate "add xx, 3". That didn't help as much as I'd hoped, but it was still a big win.
After that I made a minor tweak to the way that loops are handled to compare at the end of the loop as well as the start, and that shaved off a fraction of a second.
As things stand I think I'm "done". It might be nice to convert the generated assembly language to something gcc can handle, to drop the dependency on nasm, but I don't feel a pressing need for that yet.
Was a fun learning experience, and I think I'll come back to optimization later.
Tags: assembly, brainfuck, compilers, golang
|
16 September 2020 21:00
Four years ago somebody posted a comment-thread describing how you could start writing a little reverse-polish calculator, in C, and slowly improve it until you had written a minimal FORTH-like system:
At the time I read that comment I'd just hacked up a simple FORTH REPL of my own, in Perl, and I said "thanks for posting". I was recently reminded of this discussion, and decided to work through the process.
Using only minimal outside resources the recipe worked as expected!
The end-result is I have a working FORTH-lite, or FORTH-like, interpreter written in around 2000 lines of golang! Features include:
- Reverse-Polish mathematical operations.
- Comments between
( and ) are ignored, as expected.
- Single-line comments
\ to the end of the line are also supported.
- Support for floating-point numbers (anything that will fit inside a
float64).
- Support for printing the top-most stack element (
., or print).
- Support for outputting ASCII characters (
emit).
- Support for outputting strings (
." Hello, World ").
- Support for basic stack operations (
drop, dup, over, swap)
- Support for loops, via
do/loop.
- Support for conditional-execution, via
if, else, and then.
- Load any files specified on the command-line
- If no arguments are included run the REPL
- A standard library is loaded, from the present directory, if it is present.
To give a flavour here we define a word called star which just outputs a single start-character:
: star 42 emit ;
Now we can call that (NOTE: We didn't add a newline here, so the REPL prompt follows it, that's expected):
> star
*>
To make it more useful we define the word "stars" which shows N stars:
> : stars dup 0 > if 0 do star loop else drop then ;
> 0 stars
> 1 stars
*> 2 stars
**> 10 stars
**********>
This example uses both if to test that the parameter on the stack was greater than zero, as well as do/loop to handle the repetition.
Finally we use that to draw a box:
> : squares 0 do over stars cr loop ;
> 4 squares
****
****
****
****
> 10 squares
**********
**********
**********
**********
**********
**********
**********
**********
**********
**********
For fun we allow decompiling the words too:
> #words 0 do dup dump loop
..
Word 'square'
0: dup
1: *
Word 'cube'
0: dup
1: square
2: *
Word '1+'
0: store 1.000000
2: +
Word 'test_hot'
0: store 0.000000
2: >
3: if
4: [cond-jmp 7.000000]
6: hot
7: then
..
Anyway if that is at all interesting feel free to take a peak. There's a bit of hackery there to avoid the use of return-stacks, etc. Compared to gforth this is actually more featureful in some areas:
- I allow you to use conditionals in the REPL - outside a word-definition.
- I allow you to use loops in the REPL - outside a word-definition.
Find the code here:
Tags: forth, github, go, golang, hackernews
|
22 September 2020 13:00
So my previous post was all about implementing a simple FORTH-like language. Of course the obvious question is then "What do you do with it"?
So I present one possible use - turtle-graphics:
\ Draw a square of the given length/width
: square
dup dup dup dup
4 0 do
forward
90 turn
loop
;
\ pen down
1 pen
\ move to the given pixel
100 100 move
\ draw a square of width 50 pixels
50 square
\ save the result (png + gif)
save
Exciting times!
Tags: forth, github, go, golang, turtle
|
3 October 2020 13:00
Recently I've been writing a couple of simple compilers, which take input in a particular format and generate assembly language output. This output can then be piped through gcc to generate a native executable.
Public examples include this trivial math compiler and my brainfuck compiler.
Of course there's always the nagging thought that relying upon gcc (or nasm) is a bit of a cheat. So I wondered how hard is it to write an assembler? Something that would take assembly-language program and generate a native (ELF) binary?
And the answer is "It isn't hard, it is just tedious".
I found some code to generate an ELF binary, and after that assembling simple instructions was pretty simple. I remember from my assembly-language days that the encoding of instructions can be pretty much handled by tables, but I've not yet gone into that.
(Specifically there are instructions like "add rax, rcx", and the encoding specifies the source/destination registers - with different forms for various sized immediates.)
Anyway I hacked up a simple assembler, it can compile a.out from this input:
.hello DB "Hello, world\n"
.goodbye DB "Goodbye, world\n"
mov rdx, 13 ;; write this many characters
mov rcx, hello ;; starting at the string
mov rbx, 1 ;; output is STDOUT
mov rax, 4 ;; sys_write
int 0x80 ;; syscall
mov rdx, 15 ;; write this many characters
mov rcx, goodbye ;; starting at the string
mov rax, 4 ;; sys_write
mov rbx, 1 ;; output is STDOUT
int 0x80 ;; syscall
xor rbx, rbx ;; exit-code is 0
xor rax, rax ;; syscall will be 1 - so set to xero, then increase
inc rax ;;
int 0x80 ;; syscall
The obvious omission is support for "JMP", "JMP_NZ", etc. That's painful because jumps are encoded with relative offsets. For the moment if you want to jump:
push foo ; "jmp foo" - indirectly.
ret
:bar
nop ; Nothing happens
mov rbx,33 ; first syscall argument: exit code
mov rax,1 ; system call number (sys_exit)
int 0x80 ; call kernel
:foo
push bar ; "jmp bar" - indirectly.
ret
I'll update to add some more instructions, and see if I can use it to handle the output I generate from a couple of other tools. If so that's a win, if not then it was a fun learning experience:
Tags: asm, assembly, github, go, golang
|
2 December 2021 17:00
I realize it has been quite some time since I last made a blog-post, so I guess the short version is "I'm still alive", or as Granny Weatherwax would have said:
I ATE'NT DEAD
Of course if I die now this would be an awkward post!
I can't think of anything terribly interesting I've been doing recently, mostly being settled in my new flat and tinkering away with things. The latest "new" code was something for controlling mpd via a web-browser:
This is a simple HTTP server which allows you to minimally control mpd running on localhost:6600. (By minimally I mean literally "stop", "play", "next track", and "previous track").
I have all my music stored on my desktop, I use mpd to play it locally through a pair of speakers plugged into that computer. Sometimes I want music in the sauna, or in the bedroom. So I have a couple of bluetooth speakers which are used to send the output to another room. When I want to skip tracks I just open the mpd-web site on my phone and tap the button. (I did look at android mpd-clients, but at the same time it seemed like installing an application for this was a bit overkill).
I guess I've not been doing so much "computer stuff" outside work for a year or so. I guess lack of time, lack of enthusiasm/motivation.
So looking forward to things? I'll be in the UK for a while over Christmas, barring surprises. That should be nice as I'll get to see family, take our child to visit his grandparents (on his birthday no less) and enjoy playing the "How many Finnish people can I spot in the UK?" game
Tags: golang, mpd, mpd-web, not dead
|
21 June 2022 13:00
Recently I was reading Antirez's piece TCL the Misunderstood again, which is a nice defense of the utility and value of the TCL language.
TCL is one of those scripting languages which used to be used a hell of a lot in the past, for scripting routers, creating GUIs, and more. These days it quietly lives on, but doesn't get much love. That said it's a remarkably simple language to learn, and experiment with.
Using TCL always reminds me of FORTH, in the sense that the syntax consists of "words" with "arguments", and everything is a string (well, not really, but almost. Some things are lists too of course).
A simple overview of TCL would probably begin by saying that everything is a command, and that the syntax is very free. There are just a couple of clever rules which are applied consistently to give you a remarkably flexible environment.
To get started we'll set a string value to a variable:
set name "Steve Kemp"
=> "Steve Kemp"
Now you can output that variable:
puts "Hello, my name is $name"
=> "Hello, my name is Steve Kemp"
OK, it looks a little verbose due to the use of set, and puts is less pleasant than print or echo, but it works. It is readable.
Next up? Interpolation. We saw how $name expanded to "Steve Kemp" within the string. That's true more generally, so we can do this:
set print pu
set me ts
$print$me "Hello, World"
=> "Hello, World"
There "$print" and "$me" expanded to "pu" and "ts" respectively. Resulting in:
puts "Hello, World"
That expansion happened before the input was executed, and works as you'd expect. There's another form of expansion too, which involves the [ and ] characters. Anything within the square-brackets is replaced with the contents of evaluating that body. So we can do this:
puts "1 + 1 = [expr 1 + 1]"
=> "1 + 1 = 2"
Perhaps enough detail there, except to say that we can use { and } to enclose things that are NOT expanded, or executed, at parse time. This facility lets us evaluate those blocks later, so you can write a while-loop like so:
set cur 1
set max 10
while { expr $cur <= $max } {
puts "Loop $cur of $max"
incr cur
}
Anyway that's enough detail. Much like writing a FORTH interpreter the key to implementing something like this is to provide the bare minimum of primitives, then write the rest of the language in itself.
You can get a usable scripting language with only a small number of the primitives, and then evolve the rest yourself. Antirez also did this, he put together a small TCL interpreter in C named picol:
Other people have done similar things, recently I saw this writeup which follows the same approach:
So of course I had to do the same thing, in golang:
My code runs the original code from Antirez with only minor changes, and was a fair bit of fun to put together.
Because the syntax is so fluid there's no complicated parsing involved, and the core interpreter was written in only a few hours then improved step by step.
Of course to make a language more useful you need I/O, beyond just writing to the console - and being able to run the list-operations would make it much more useful to TCL users, but that said I had fun writing it, it seems to work, and once again I added fuzz-testers to the lexer and parser to satisfy myself it was at least somewhat robust.
Feedback welcome, but even in quiet isolation it's fun to look back at these "legacy" languages and recognize their simplicity lead to a lot of flexibility.
Tags: github, golang, tcl
|
1 July 2022 19:00
So my previous post introduced a trivial interpreter for a TCL-like language.
In the past week or two I've cleaned it up, fixed a bunch of bugs, and added 100% test-coverage. I'm actually pretty happy with it now.
One of the reasons for starting this toy project was to experiment with how easy it is to extend the language using itself
Some things are simple, for example replacing this:
puts "3 x 4 = [expr 3 * 4]"
With this:
Just means defining a function (proc) named *. Which we can do like so:
proc * {a b} {
expr $a * $b
}
(Of course we don't have lists, or variadic arguments, so this is still a bit of a toy example.)
Doing more than that is hard though without support for more primitives written in the parent language than I've implemented. The obvious thing I'm missing is a native implementation of upvalue, which is TCL primitive allowing you to affect/update variables in higher-scopes. Without that you can't write things as nicely as you would like, and have to fall back to horrid hacks or be unable to do things.
# define a procedure to run a body N times
proc repeat {n body} {
set res ""
while {> $n 0} {
decr n
set res [$body]
}
$res
}
# test it out
set foo 12
repeat 5 { incr foo }
# foo is now 17 (i.e. 12 + 5)
A similar story implementing the loop word, which should allow you to set the contents of a variable and run a body a number of times:
proc loop {var min max bdy} {
// result
set res ""
// set the variable. Horrid.
// We miss upvalue here.
eval "set $var [set min]"
// Run the test
while {<= [set "$$var"] $max } {
set res [$bdy]
// This is a bit horrid
// We miss upvalue here, and not for the first time.
eval {incr "$var"}
}
// return the last result
$res
}
loop cur 0 10 { puts "current iteration $cur ($min->$max)" }
# output is:
# => current iteration 0 (0-10)
# => current iteration 1 (0-10)
# ...
That said I did have fun writing some simple test-cases, and implementing assert, assert_equal, etc.
In conclusion I think the number of required primitives needed to implement your own control-flow, and run-time behaviour, is a bit higher than I'd like. Writing switch, repeat, while, and similar primitives inside TCL is harder than creating those same things in FORTH, for example.
Tags: github, golang, tcl
|
3 November 2022 22:00
So this week I recycled a talk I'd given in the past, about how even using
extremely simple parsers allows a lot of useful static-analysis to be done,
for specific niche use-cases.
This included examples of scanning comments above classes to ensure they
referred to the appropriate object, ensuring that specific function
calls always included a specific (optional) parameter, etc.
Nothing too complex, but I figured I'd give a new example this time, and
I remembered I'd recently written a bunch of functions for an interpreter
which I'd ordered quite deliberately.
Assume you're writing a BASIC interpreter, you need to implement a bunch of
built-in maths functions such as SIN, COS, TAN, then some string-related
functions LEFT$, RIGHT$, MID$, etc.
When it comes to ordering there are a couple of approaches:
- Stick them all in one package:
- Create a package and group them:
builtins/maths.gobuiltins/string.go- .. etc
Personal preference probably dictates the choice you make, but either way I think it would be rational and obvious that you'd put the functions in alphabetical order:
func ABS( args []primitive.Object) (primitive.Object, error) {
..}
func COS( args []primitive.Object) (primitive.Object, error) {
..}
func SIN( args []primitive.Object) (primitive.Object, error) {
..}
func TAN( args []primitive.Object) (primitive.Object, error) {
..}
I did that myself, and I wrote a perl-script to just parse the file using a simple regexp "^func\s+([^(]+)\(" but then I figured this was a good time to write a real static-analysis tool.
The golang environment is full of trivial little linters for various purposes, and the standard "go vet .." driver makes it easy to invoke them. Realizing that I was going to get driven in the same way it was obvious I'd write something called "alphaVet".
So anyway, half written for a talk, half-written because of the name:
- Golang linter that reports failures if functions aren't in alphabetical order
Tags: alphavet, golang, linting
|
28 November 2022 22:00
I recently wrote about yet another lisp I'd
been having fun with.
Over the past couple of years I've played with a few toy scripting languages,
or random interpreters, and this time I figured I'd do something beyond the
minimum, by implementing the Language Server Protocol.
In brief the language server protocol (LSP) is designed to abstract
functionality that might be provided by an editor, or IDE, into a small
"language server". If the language-server knows how to jump to definitions,
provide completion, etc, etc, then the editor doesn't need to implement those
things for NN different languages - it just needs to launch and communicate
with something that does know how to do the job.
Anyway LSP? LISP? Only one letter different, so that's practically enough
reason to have a stab at it.
Thankfully I found a beautiful library that implements a simple framework
allowing the easy implementation of a golang-based LSP-serverÖ
Using that I quickly hacked up a server that can provide:
- Overview of all standard-library functions, on hover.
- Completion of all standard-library functions.
I've tested this in both GNU Emacs and Neovim, so that means I'm happy
I support all editors! (More seriously if it works in two then that
probably means that the LSP stuff should work elsewhere too.)
Here's what the "help on hover" looks like, within Emacs:

Vim looks similar but you have to press K to see the wee popup. Still
kinda cute, and was a good experiment.
Tags: golang, lisp, lsp
|
|





{kind=link}