|
Entries tagged github
29 December 2012 21:50
A couple of days ago I made a new release of slaughter, to add a new primitive I was sorely missing:
if ( 1 != IdenticalContents( File1 => "/etc/foo" ,
File2 => "/etc/bar" ) )
{
# do something because the file contents differ
}
This allows me to stop blindly over-writing files if they are identical already.
As part of that work I figured I should be more "visible", so on that basis I've done two things:
After sanity-checking my policies I'm confident I'm not leaking anything I wish to keep private - but there is some news being disclosed ;)
Now that is done I think there shouldn't be any major slaughter-changes for the forseeable future; I'm managing about ten hosts with it now, and being perl it suits my needs. The transport system is flexible enough to suit most folk, and there are adequate facilities for making local additions without touching the core so if people do want to do new things they don't need me to make changes - hopefully.
ObQuote: "Yippee-ki-yay" - Die Hard, the ultimate Christmas film.
Tags: github, slaughter
|
30 December 2012 21:50
People seemed interested in my mini-reviews of static-site
generators.
I promised to review more in the future, and so to shame myself into
doing so I present:
As you can see I've listed my requirements, and I've included a
project for each of the tools I've tested.
I will continue to update as I go through more testing. As
previously mentioned symlink-handling is the thing that kills a lot of
tools.
Tags: github, templer
|
24 March 2013 21:50
So via hackernews I recently learned about fight code, and my efforts have been fun. Currently my little robot is ranked ~400, but it seems to jump around a fair bit.
Otherwise I've done little coding recently:
I'm pondering libpcap a little, for work purposes. There is a plan to write a deamon which will count incoming SYN packets, per-IP, and drop access to clients that make "too many" requests "too quickly".
This plan is a simple anti-DoS tool which might or might not work in the real world. We do have a couple of clients that seem to be DoS magnets and this is better than using grep + sort against apache access logs.
For cases where a small number of source IPs make many-many requests it will help. For the class of attacks where a huge botnet has members making only a couple of requests each it won't do anything useful.
We'll see how it turns out.
Tags: bookmarks, coding, github
|
16 April 2013 21:50
This may be useful, may become useful, or may not:
Tags: github
|
11 May 2013 21:50
Lumail <http://lumail.org> received two patches today, one to build on Debian Unstable, and one to build on OpenBSD.
The documentation of the lua
primitives is almost 100% complete, and the repository has now got a public list of issues which I'm slowly working on.
Even though I can't reply to messages I'm cheerfully running it on my mail box as a mail-viewer. Faster than mutt. Oddly enough. Or maybe I'm just biased.
Tags: github, lumail
|
14 May 2013 21:50
Today my main machine was down for about 8 hours. Oops.
That meant when I got home, after a long and dull train journey, I received a bunch of mails from various hosts each saying:
- Failed to fetch slaughter policies from rsync://www.steve.org.uk/slaughter
Slaughter is my sysadmin utility which pulls policies/recipies from a central location and applies them to the local host.
Slaughter has a bunch of different transports, which are the means by which policies and files are transferred from the remote "central host" to the local machine. Since git is supported I've now switched my policies to be fetched from the master github repository.
This means:
- All my servers need git installed. Which was already the case.
- I can run one less service on my main box.
- We now have a contest: Is my box more reliable than github?
In other news I've fettled with lumail a bit this week, but I'm basically doing nothing until I've pondered my way out of the hole I've dug myself into.
Like mutt lumail has the notion of "limiting" the display of things:
- Show all maildirs.
- Show all maildirs with new mail in them.
- Show all maildirs that match a pattern.
- Show all messages in the currently selected folder(s)
- More than one folder may be selected :)
- Shall all unread messages in the currently selected folder(s).
Unfortunately the latter has caused an annoying, and anticipated, failure case. If you open a folder and cause it to only show unread messages all looks good. Until you read a message. At which point it is no longer allowed to be displayed, so it disappears. Since you were reading a message the next one is opened instead. WHich then becomes marked as read, and no longer should be displayed, because we've said "show me new/unread-only messages please".
The net result is if you show only unread messages and make the mistake of reading one .. you quickly cycle through reading all of them, and are left with an empty display. As each message in turn is opened, read, and marked as non-new.
There are solutions, one of which I documented on the issue. But this has a bad side-effect that message navigation is suddenly complicated in ways that are annoying.
For the moment I'm mulling the problem over and I will only make trivial cleanup changes until I've got my head back in the game and a good solution that won't cause me more pain.
Tags: github, lumail, slaughter, sysadmin
|
26 August 2013 21:50
Github is a nice site, and I routinely monitor a couple of projects there.
I've also been using it to host a couple of my own projects, initially as an experiment, but since then because it has been useful to get followers and visibility.
I'm a little disappointed that you don't get to see more data though; today my sysadmin utilities repository received several new "stars". Given that these all occurred "an hour ago" it seems likely that they we referenced in a comment somewhere on LWN, hacker news, or similar.
Unfortunately I've no clue where that happened, or if it was a coincidence.
I expect this is more of a concern for those users who use github-pages, where having access to the access.logs would be more useful still. But ..
Tags: github, sysadmin-util
|
6 December 2013 21:50
I just realised a lot of my projects are deployed in the same way:
- They run under runit.
- They operate directly from git clones.
This includes both Apache-based projects, and node.js projects.
I'm sure I could generalize this, and do clever things with git-hooks. Right now for example I have run-scripts which look like this:
#!/bin/sh
#
# /etc/service/blogspam.js/run - Runs the blogspam.net API.
#
# update the repository.
git pull --update --quiet
# install dependencies, if appropriate.
npm install
# launche
exec node server.js
It seems the only thing that differs is the name of the directory and the remote git clone URL.
With a bit of scripting magic I'm sure you could push applications to a virgin Debian installation and have it do the right thing.
I think the only obvious thing I'm missing is a list of Debian dependencies. Perhaps adding soemthing like the packages.json file I could add an extra step:
apt-get update -qq
apt-get install --yes --force-yes $(cat packages.apt)
Making deployments easy is a good thing, and consistency helps..
Tags: github, node, pass, random
|
29 December 2013 21:50
This week my small collection of sysadmin tools received a lot of attention; I've no idea what triggered it, but it ended up on the front-page of github as a "trending repository".
Otherwise I've recently spent some time "playing about" with some security stuff. My first recent report wasn't deemed worthy of a security update, but it was still a fun one. From the package description rush is described as:
GNU Rush is a restricted shell designed for sites providing only limited access to resources for remote users. The main binary executable is configurable as a user login shell, intended for users that only are allowed remote login to the system at hand.
As the description says this is primarily intended for use by remote users, but if it is installed locally you can read "any file" on the local system.
How? Well the program is setuid(root) and allows you to specify an arbitrary configuration file as input. The very very first thing I tried to do with this program was feed it an invalid and unreadable-to-me configuration file.
Helpfully there is a debugging option you can add --lint to help you setup the software. Using it is as simple as:
shelob ~ $ rush --lint /etc/shadow
rush: Info: /etc/shadow:1: unknown statement: root:$6$zwJQWKVo$ofoV2xwfsff...Mxo/:15884:0:99999:7:::
rush: Info: /etc/shadow:2: unknown statement: daemon:*:15884:0:99999:7:::
rush: Info: /etc/shadow:3: unknown statement: bin:*:15884:0:99999:7:::
rush: Info: /etc/shadow:4: unknown statement: sys:*:15884:0:99999:7:::
..
How nice?
The only mitigating factor here is that only the first token on the line is reported - In this case we've exposed /etc/shadow which doesn't contain whitespace for the interesting users, so it's enough to start cracking those password hashes.
If you maintain a setuid binary you must be trying things like this.
If you maintain a setuid binary you must be confident in the codebase.
People will be happy to stress-test, audit, examine, and help you - just ask.
Simple security issues like this are frankly embarassing.
Anyway that's enough: #733505 / CVE-2013-6889.
Tags: github, random, security
|
3 March 2014 21:50
I get all excited when I load up Github's front-page and see something like:
"robyn has forked skx/xxx to robyn/xxx"
I wonder what they will do, what changes do they have in mind?
Days pass, and no commits happen.
Anti-social coding: Cloning the code, I guess in case I delete my repository, but not intending to make any changes.
Tags: github
|
6 March 2014 21:50
This week I received a logitech squeezebox radio, which is basically an expensive toy that allows you to listen to either "internet radio", or music streamed from your own PC via a portable device that accesses the network wirelessly.
The main goal of this purchase was to allow us to listen to media stored on a local computer in the bedroom, or living-room.
The hardware scans your network looking for a media server, so the first step is to install that:
The media-server has a couple of open ports; one for streaming the media, and one for a user-browsable HTML interface. Interestingly the radio-device shows up in the web-interface, so you can mess around with the currently loaded playlist from your office, while your wife is casually listening to music in the bedroom. (I'm not sure if that's a feature or not yet ;)
Although I didn't find any alternative server-implementations I did find a software-client which you can use to play music from the central server - slimp3slave - and again you can push playlists, media, etc, to this.
My impressions are pretty positive; the device was too expensive, certainly I wouldn't buy two, but it is functional. The user-interface is decent, and the software being available and open is a big win.
Downsides? No remote-control for the player, because paying an additional £70 is never going to happen, but otherwise I can't think of anything.
(Shame the squeezebox product line seems to have been cancelled (?))
Procmail Alternatives?
Although I did start hacking a C & Lua alternative, it looks like there are enough implementations out there that I don't feel so strongly any more.
I'm working in a different way to most people, rather than sort mails at delivery time I'm going to write a trivial daemon that will just watch ~/Maildir/.Incoming, and move mails out of there. That means that no errors will cause mail to be lost at SMTP/delivery time.
I'm going to base my work on Email::Filter since it offers 90% of the primitives I want. The only missing thing is the ability to filter mails via external commands which has now been reported as a bug/omission.
Tags: audio, github, perl, procmail, random, squeezebox, streaming
|
25 August 2014 21:50
To round up the discussion of the Debian Administration site yesterday I flipped the switch on the load-balancing. Rather than this:
https -> pound \
\
http -------------> varnish --> apache
We now have the simpler route for all requests:
http -> haproxy -> apache
https -> haproxy -> apache
This means we have one less HTTP-request for all incoming secure connections, and these days secure connections are preferred since a Strict-Transport-Security header is set.
In other news I've been juggling git repositories; I've setup an installation of GitBucket on my git-host. My personal git repository used to contain some private repositories and some mirrors.
Now it contains mirrors of most things on github, as well as many more private repositories.
The main reason for the switch was to get a prettier interface and bug-tracker support.
A side-benefit is that I can use "groups" to organize repositories, so for example:
Most of those are mirrors of the github repositories, but some are new. When signed in I see more sources, for example the source to http://steve.org.uk.
I've been pleased with the setup and performance, though I had to add some caching and some other magic at the nginx level to provide /robots.txt, etc, which are not otherwise present.
I'm not abandoning github, but I will no longer be using it for private repositories (I was gifted a free subscription a year or three ago), and nor will I post things there exclusively.
If a single canonical source location is required for a repository it will be one that I control, maintain, and host.
I don't expect I'll give people commit access on this mirror, but it is certainly possible. In the past I've certainly given people access to private repositories for collaboration, etc.
Tags: git, github, yawns
|
29 August 2014 21:50
Yesterday I carried out the upgrade of a Debian host from Squeeze to Wheezy for a friend. I like doing odd-jobs like this as they're generally painless, and when there are problems it is a fun learning experience.
I accidentally forgot to check on the status of the MySQL server on that particular host, which was a little embarassing, but later put together a reasonably thorough serverspec recipe to describe how the machine should be setup, which will avoid that problem in the future - Introduction/tutorial here.
The more I use serverspec the more I like it. My own personal servers have good rules now:
shelob ~/Repos/git.steve.org.uk/server/testing $ make
..
Finished in 1 minute 6.53 seconds
362 examples, 0 failures
Slow, but comprehensive.
In other news I've now migrated every single one of my personal mercurial repositories over to git. I didn't have a particular reason for doing that, but I've started using git more and more for collaboration with others and using two systems felt like an annoyance.
That means I no longer have to host two different kinds of repositories, and I can use the excellent gitbucket software on my git repository host.
Needless to say I wrote a policy for this host too:
#
# The host should be wheezy.
#
describe command("lsb_release -d") do
its(:stdout) { should match /wheezy/ }
end
#
# Our gitbucket instance should be running, under runit.
#
describe supervise('gitbucket') do
its(:status) { should eq 'run' }
end
#
# nginx will proxy to our back-end
#
describe service('nginx') do
it { should be_enabled }
it { should be_running }
end
describe port(80) do
it { should be_listening }
end
#
# Host should resolve
#
describe host("git.steve.org.uk" ) do
it { should be_resolvable.by('dns') }
end
Simple stuff, but being able to trigger all these kind of tests, on all my hosts, with one command, is very reassuring.
Tags: git, github, serverspec
|
2 November 2014 21:50
I enjoy the tilde.club site/community, and since I've just setup an IPv6-only host I was looking to do something similar.
Unfortunately my (working) code to clone github repositories into per-user directories fails - because github isn't accessible over IPv6.
That's a shame.
Oddly enough chromium, the browser packaged for wheezy, doesn't want to display IPv6-only websites either. For example this site fail to load http://ipv6.steve.org.uk/.
In the meantime I've got a server setup which is only accessible over IPv6 and I'm a little smug. (http://ipv6.website/).
(Yes it is true that I've used all the IPv4 addreses allocated to my VLAN. That's just a coincidence. Ssh!)
Tags: github, ipv6
|
13 September 2015 21:50
Although I've been writing a bit recently about file-storage, this post is about something much more simple: Just making a random file or two available on an ad-hoc basis.
In the past I used to have my email and website(s) hosted on the same machine, and that machine was well connected. Making a file visible just involved running ~/bin/publish, which used scp to write a file beneath an apache document-root.
These days I use "my computer", "my work computer", and "my work laptop", amongst other hosts. The SSH-keys required to access my personal boxes are not necessarily available on all of these hosts. Add in firewall constraints and suddenly there isn't an obvious way for me to say "Publish this file online, and show me the root".
I asked on twitter but nothing useful jumped out. So I ended up writing a simple server, via sinatra which would allow:
- Login via the site, and a browser. The login-form looks sexy via bootstrap.
- Upload via a web-form, once logged in. The upload-form looks sexy via bootstrap.
- Or, entirely seperately, with HTTP-basic-auth and a HTTP POST (i.e. curl)
This worked, and was even secure-enough, given that I run SSL if you import my CA file.
But using basic auth felt like cheating, and I've been learning more Go recently, and I figured I should start taking it more seriously, so I created a small repository of learning-programs. The learning programs started out simply, but I did wire up a simple TOTP authenticator.
Having TOTP available made me rethink things - suddenly even if you're not using SSL having an eavesdropper doesn't compromise future uploads.
I'd also spent a few hours working out how to make extensible commands in go, the kind of thing that lets you run:
cmd sub-command1 arg1 arg2
cmd sub-command2 arg1 .. argN
The solution I came up with wasn't perfect, but did work, and allow the seperation of different sub-command logic.
So suddenly I have the ability to run "subcommands", and the ability to authenticate against a time-based secret. What is next? Well the hard part with golang is that there are so many things to choose from - I went with gorilla/mux as my HTTP-router, then I spend several hours filling in the blanks.
The upshot is now that I have a TOTP-protected file upload site:
publishr init - Generates the secret
publishr secret - Shows you the secret for import to your authenticator
publishr serve - Starts the HTTP daemon
Other than a lack of comments, and test-cases, it is complete. And stand-alone. Uploads get dropped into ./public, and short-links are generated for free.
If you want to take a peak the code is here:
The only annoyance is the handling of dependencies - which need to be "go got ..". I guess I need to look at godep or similar, for my next learning project.
I guess there's a minor gain in making this service available via golang. I've gained protection against replay attacks, assuming non-SSL environment, and I've simplified deployment. The downside is I can no longer login over the web, and I must use curl, or similar, to upload. Acceptible tradeoff.
Tags: file-hosting, github, go, golang, sinatra
|
3 December 2017 21:50
I've shuffled around all the repositories which are associated with the blogspam service, such that they're all in the same place and refer to each other correctly:
Otherwise I've done a bit of tidying up on virtual machines, and I'm just about to drop the use of qpsmtpd for handling my email. I've used the (perl-based) qpsmtpd project for many years, and documented how my system works in a "book":
I'll be switching to pure exim4-based setup later today, and we'll see what that does. So far today I've received over five thousand spam emails:
steve@ssh /spam/today $ find . -type f | wc -l
5731
Looking more closely though over half of these rejections are "dictionary attacks", so they're not SPAM I'd see if I dropped the qpsmtpd-layer. Here's a sample log entry (for a mail that was both rejected at SMTP-time by qpsmtpd and archived to disc in case of error):
{"from":"<[email protected]>",
"helo":"adrian-monk-v3.ics.uci.edu",
"reason":"Mail for juha not accepted at steve.fi",
"filename":"1512284907.P26574M119173Q0.ssh.steve.org.uk.steve.fi",
"subject":"Viagra Professional. Beyond compare. Buy at our shop.",
"ip":"2a00:6d40:60:814e::1",
"message-id":"<[email protected]>",
"recipient":"[email protected]",
"host":"Unknown"}
I suspect that with procmail piping to crm114, and a beefed up spam-checking configuration for exim4 I'll not see a significant difference and I'll have removed something non-standard. For what it is worth over 75% of the remaining junk which was rejected at SMTP-time has been rejected via DNS-blacklists. So again exim4 will take care of that for me.
If it turns out that I'm getting inundated with junk-mail I'll revert this, but I suspect that it'll all be fine.
Tags: blogspam, exim4, github, mail-scanning, perl, qpsmtpd
|
31 January 2019 15:01
I've spent some time in the recent past working with interpreters, and writing a BASIC interpreter, but one thing I'd not done is write a compiler.
Once upon a time I worked for a compiler-company, but I wasn't involved with the actual coding at that time. Instead I worked on other projects, and did a minor amount of system-administration.
There are enough toy-languages that it didn't seem worthwhile to write a compiler for yet another one. At the same time writing a compiler for a full-language would get bogged down in a lot of noise.
So I decided to simplify things: I would write a compiler for "maths". Something that would take an expression and output assembly-language, which could then be compiled.
The end result is this simple compiler:
Initially I wrote something that would parse expressions such as 3 + 4 * 5 and output an abstract-syntax-tree. I walked the tree and started writing logic to pick registers, and similar. It all seemed like more of a grind than a useful exercise - and considering how ludicrous compiling simple expressions to assembly language already was it seemed particularly silly.
So once again I simplified, deciding to accept only a simple "reverse-polish-like" expression, and outputing the assembly for that almost directly.
Assume you want to calculate "((3 * 5) +2)" you'd feed my compiler:
3 5 * 2 +
To compile that we first load the initial state 3, then we walk the rest of the program always applying an operation with an operand:
- Store
3
5 * -> multiply by 5.2 + -> add 2.- ..
This approach is trivial to parse, and trivial to output the assembly-language for: Pick a register and load your starting value, then just make sure all your operations apply to that particular register. (In the case of Intel assembly it made sense to store the starting value in EAX, and work with that).
A simple program would then produce a correspondingly simple output. Given 1 1 + we'd expect this output:
.intel_syntax noprefix
.global main
.data
result: .asciz "Result %d\n"
main:
mov rax, 1
add rax, 1
lea rdi,result
mov rsi, rax
xor rax, rax
call printf
xor rax, rax
ret
With that output you can assemble the program, and run it:
$ gcc -static -o program program.s
$ ./program
Result 2
I wrote some logic to allow calculating powers too, so you can output 2 ^ 8, etc. That's just implemented the naive-way, where you have a small loop and multiply the contents of EAX by itself the appropriate number of times. Modulus is similarly simple to calculate.
Adding support for named variables, and other things, wouldn't be too hard. But it would involve register-allocation and similar complexity. Perhaps that's something I need to flirt with, to make the learning process complete, but to be honest I can't be bothered.
Anyway check it out, if you like super-fast maths. My benchmark?
$ time perl -e 'print 2 ** 8 . "\n"'
256
real 0m0.006s
user 0m0.005s
sys 0m0.000s
vs.
$ math-compiler -compile '2 8 ^'
$ time ./a.out
Result 256
real 0m0.001s
user 0m0.001s
sys 0m0.000s
Wow. Many wow. Much speed. All your base-two are belong to us.
Tags: compilers, github, golang, math, toy
|
16 February 2019 18:26
The simple math-compiler I introduced in my previous post has had a bit of an overhaul, so that now it is fully RPN-based.
Originally the input was RPN-like, now it is RPN for real. It handles error-detection at run-time, and generates a cleaner assembly-language output:
In other news I bought a new watch, which was a fun way to spend some time.
I love mechanical watches, clocks, and devices such as steam-engines. While watches are full of tiny and intricate parts I like the pretence that you can see how they work, and understand them. Steam engines are seductive because their operation is similar; you can almost look at them and understand how they work.
I've got a small collection of watches at the moment, ranging from €100-€2000 in price, these are universally skeleton-watches, or open-heart watches.
My recent purchase is something different. I was looking at used Rolexs, and found some from 1970s. That made me suddenly wonder what had been made the same year as I was born. So I started searching for vintage watches, which had been manufactured in 1976. In the end I found a nice Soviet Union piece, made by Raketa. I can't prove that this specific model was actually manufactured that year, but I'll keep up the pretence. If it is +/- 10 years that's probably close enough.
My personal dream-watch is the Rolex Oyster (I like to avoid complications). The Oyster is beautiful, and I can afford it. But even with insurance I'd feel too paranoid leaving the house with that much money on my wrist. No doubt I'll find a used one, for half that price, sometime. I'm not in a hurry.
(In a horological-sense a "complication" is something above/beyond the regular display of time. So showing the day, the date, or phase of the moon would each be complications.)
Tags: compilers, github, golang, math, watches
|
26 February 2019 12:01
Recently I heared that travis-CI had been
bought out, and later that
they'd started to fire their staff.
I've used Travis-CI for a few years now, via github, to automatically build
binaries for releases, and to run tests.
Since I was recently invited to try the Github Actions beta I figured it was time to experiment.
Github actions allow you to trigger "stuff" on "actions". Actions are things
like commits being pushed to your repository, new releases appearing, and so on. "Stuff" is basically "launch a specific docker container".
The specified docker container has a copy of your project repository cloned into it, and you can operate upon it pretty freely.
I created two actions (which basically means I authored two Dockerfiles), and setup the meta-information, so that now I can do what I used to do with travis easily:
- github-action-tester
- Allows tests to be run whenever a new commit is pushed to your repository.
- Or whenever a pull-request is submitted, or updated.
- github-actions-publish-binaries
- If you create a new release in the github UI your project is built, and the specified binaries are attached to the release.
Configuring these in the repository is very simple, you have to define a workflow at .github/main.workflow, and my projects tend to look very similar:
# pushes trigger the testsuite
workflow "Push Event" {
on = "push"
resolves = ["Test"]
}
# pull-requests trigger the testsuite
workflow "Pull Request" {
on = "pull_request"
resolves = ["Test"]
}
# releases trigger new binary artifacts
workflow "Handle Release" {
on = "release"
resolves = ["Upload"]
}
##
## The actions
##
##
## Run the test-cases, via .github/run-tests.sh
##
action "Test" {
uses = "skx/github-action-tester@master"
}
##
## Build the binaries, via .github/build, then upload them.
##
action "Upload" {
uses = "skx/github-action-publish-binaries@master"
args = "math-compiler-*"
secrets = ["GITHUB_TOKEN"]
}
In order to make the actions generic they both execute a shell-script inside your repository. For example the action to run the tests just executes
That way you can write the tests that make sense. For example a golang application would probably run go test ..., but a C-based system might run make test.
Similarly the release-making action runs .github/build, and assumes that will produce your binaries, which are then uploaded.
The upload-action requires the use of a secret, but it seems to be handled by
magic - I didn't create one. I suspect GITHUB_TOKEN is a magic-secret which
is generated on-demand.
Anyway I updated a few projects, and you can see their configuration by looking at .github within the repository:
All in all it was worth the few hours I spent on it, and now I no longer use Travis-CI. The cost? I guess now I'm tied to github some more...
Tags: automation, github, golang, travis
|
1 August 2019 13:01
This is part three in my slow journey towards creating a home-brew
Z80-based computer. My previous
post
demonstrated writing some simple code, and getting it running under an
emulator. It also described my planned approach:
- Hookup a Z80 processor to an Arduino Mega.
- Run code on the Arduino to emulate RAM reads/writes and I/O.
- Profit, via the learning process.
I expect I'll have to get my hands-dirty with a breadboard and naked
chips in the near future, but for the moment I decided to start with the
least effort. Erturk Kocalar has a website where he
sells "shields"
(read: expansion-boards) which contain a Z80, and which is designed to
plug into an Arduino Mega with no fuss. This is a simple design, I've
seen a bunch of people demonstrate how to wire up by hand, for example
this post.
Anyway I figured I'd order one of those, and get started on the easy-part, the software. There was some sample code available from Erturk, but it wasn't ideal from my point of view because it mixed driving the Z80 with doing "other stuff". So I abstracted the core code required to interface with the Z80 and packaged it as a simple library.
The end result is that I have a z80 retroshield library which uses an Arduino mega to drive a Z80 with something as simple as this:
#include <z80retroshield.h>
//
// Our program, as hex.
//
unsigned char rom[32] =
{
0x3e, 0x48, 0xd3, 0x01, 0x3e, 0x65, 0xd3, 0x01, 0x3e, 0x6c, 0xd3, 0x01,
0xd3, 0x01, 0x3e, 0x6f, 0xd3, 0x01, 0x3e, 0x0a, 0xd3, 0x01, 0xc3, 0x16,
0x00
};
//
// Our helper-object
//
Z80RetroShield cpu;
//
// RAM I/O function handler.
//
char ram_read(int address)
{
return (rom[address]) ;
}
// I/O function handler.
void io_write(int address, char byte)
{
if (address == 1)
Serial.write(byte);
}
// Setup routine: Called once.
void setup()
{
Serial.begin(115200);
//
// Setup callbacks.
//
// We have to setup a RAM-read callback, otherwise the program
// won't be fetched from RAM and executed.
//
cpu.set_ram_read(ram_read);
//
// Then we setup a callback to be executed every time an "out (x),y"
// instruction is encountered.
//
cpu.set_io_write(io_write);
//
// Configured.
//
Serial.println("Z80 configured; launching program.");
}
//
// Loop function: Called forever.
//
void loop()
{
// Step the CPU.
cpu.Tick();
}
All the logic of the program is contained in the Arduino-sketch, and all
the use of pins/ram/IO is hidden away. As a recap the Z80 will make
requests for memory-contents, to fetch the instructions it wants to
execute. For general purpose input/output there are two instructions
that are used:
IN A, (1) ; Read a character from STDIN, store in A-register.
OUT (1), A ; Write the character in A-register to STDOUT
Here 1 is the I/O address, and this is an 8 bit number. At the moment
I've just configured the callback such that any write to I/O address 1
is dumped to the serial console.
Anyway I put together a couple of examples of increasing complexity, allowing me to prove that RAM read/writes work, and that I/O reads and writes work.
I guess the next part is where I jump in complexity:
- I need to wire a physical Z80 to a board.
- I need to wire a PROM to it.
- This will contain the program to be executed - hardcoded.
- I need to provide power, and a clock to make the processor tick.
With a bunch of LEDs I'll have a Z80-system running, but it'll be
isolated and hard to program. (Since I'll need to reflash the
RAM/ROM-chip).
The next step would be getting it hooked up to a serial-console of some
sort. And at that point I'll have a genuinely programmable standalone
Z80 system.
Tags: arduino, arduino mega, computer-building, github, gitlab, retroshield, z80
|
1 November 2019 16:00
For the past few years I've been keeping a work-log of everything I do. I don't often share these, though it is sometimes interesting to be able to paste into a chat-channel "Oh on the 17th March I changed that .."
I've had a couple of different approaches but for the past few years I've mostly settled upon emacs ~/Work.md. I just create a heading for the date and I'm done:
# 10-03-2019
* Did a thing.
* See this link
* Did another thing.
## Misc.
Happy Birthday to me.
As I said I've been doing this for years, but it was only last week that I decided to start making it more efficient. Since I open this file often I should bind it to a key:
(defun worklog()
(interactive "*")
(find-file "~/Work.MD"))
(global-set-key (kbd "C-x w") 'worklog)
This allows me to open the log by just pressing C-x w. The next step was to automate the headers. So I came up with a function which will search for today's date, adding it if missing:
(defun worklog-today()
"Move to today's date, if it isn't found then append it"
(interactive "*")
(beginning-of-buffer)
(if (not (search-forward (format-time-string "# %d-%m-%Y") nil t 1))
(progn
(end-of-buffer)
(insert (format-time-string "\n\n# %d-%m-%Y\n")))))
Now we use some magic to makes this function run every time I open ~/Work.md:
(defun worklog_hook ()
(when (equalp (file-name-nondirectory (buffer-file-name)) "work.md")
(worklog-today)
)
)
(add-hook 'find-file-hook 'worklog_hook)
Finally there is a useful package imenu-list which allows you to create an inline sidebar for files. Binding that to a key allows it to be toggled easily:
(add-hook 'markdown-mode-hook
(lambda ()
(local-set-key (kbd "M-'") 'imenu-list-smart-toggle)
The end result is a screen that looks something like this:
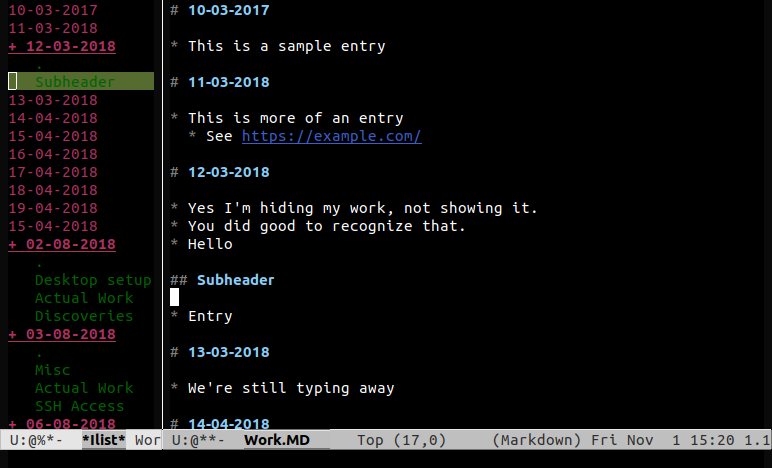
If you have an interest in such things I store my emacs configuration on github, in a dotfile-repository. My init file is writting in markdown, which makes it easy to read:
Tags: emacs, github, lisp, markdown
|
16 January 2020 19:19
myrepos is an excellent tool for applying git operations to multiple repositories, and I use it extensively.
Given a configuration file like this:
..
[github.com/skx/asql]
checkout = git clone [email protected]:skx/asql.git
[github.com/skx/bookmarks.public]
checkout = git clone [email protected]:skx/bookmarks.public.git
[github.com/skx/Buffalo-220-NAS]
checkout = git clone [email protected]:skx/Buffalo-220-NAS.git
[github.com/skx/calibre-plugins]
checkout = git clone [email protected]:skx/calibre-plugins.git
...
You can clone all the repositories with one command:
mr -j5 --config .mrconfig.github checkout
Then pull/update them them easily:
mr -j5 --config .mrconfig.github update
It works with git repositories, mercurial, and more. (The -j5 argument means to run five jobs in parallel. Much speed, many fast. Big wow.)
I wrote a simple golang utility to use the github API to generate a suitable configuration including:
- All your personal repositories.
- All the repositories which belong to organizations you're a member of.
Currently it only supports github, but I'll update to include self-hosted and API-compatible services such as gitbucket. Is there any interest in such a tool? Or have you all written your own already?
(I have the feeling I've written this tool in Perl, Ruby, and even using curl a time or two already. This time I'll do it properly and publish it to save effort next time!)
Tags: github, golang, mr, myrepos
|
17 January 2020 19:19
myrepos is an excellent tool for applying git operations to multiple repositories, and I use it extensively.
I've written several scripts to dump remote repository-lists into a suitable configuration format, and hopefully I've done that for the last time.
github2mr correctly handles:
- Exporting projects from Github.com
- Exporting projects from (self-hosted installations of) Github Enterprise.
- Exporting projects from (self-hosted installations of) Gitbucket.
If it can handle Gogs, Gitea, etc, then I'd love to know, otherwise patches are equally welcome!
Tags: github, github2mr, golang, mr, myrepos
|
7 April 2020 09:00
Over the past few weeks things have been pretty hectic. Since I'm not working at the moment I'm mostly doing childcare instead. I need a break, now and again, so I've been sending our child to päiväkoti two days a week with him home the rest of the time.
I love taking care of the child, because he's seriously awesome, but it's a hell of a lot of work when most of our usual escapes are unavailable. For example we can't go to the (awesome) Helsinki Central Library as that is closed.
Instead of doing things outdoors we've been baking bread together, painting, listening to music and similar. He's a big fan of any music with drums and shouting, so we've been listening to Rammstein, The Prodigy, and as much Queen as I can slip in without him complaining ("more bang bang!").
I've also signed up for some courses at the Helsinki open university, including Devops with Docker so perhaps I have a future career working with computers? I'm hazy.
Finally I saw a fun post the other day on reddit asking about the creation of a DSL for server-setup. I wrote a reply which basically said two things:
- First of all you need to define the minimum set of primitives you can execute.
- (Creating a file, fetching a package, reloading services when a configuration file changes, etc.)
- Then you need to define a syntax for expressing those rules.
- Not using YAML. Because Ansible fucked up bigtime with that.
- It needs to be easy to explain, it needs to be consistent, and you need to decide before you begin if you want "toy syntax" or "programming syntax".
- Because adding on conditionals, loops, and similar, will ruin everything if you add it once you've started with the wrong syntax. Again, see Ansible.
Anyway I had an idea of just expressing things in a simple fashion, borrowing Puppet syntax (which I guess is just Ruby hash literals). So a module to do stuff with files would just look like this:
file { name => "This is my rule",
target => "/tmp/blah",
ensure => "absent" }
The next thing to do is to allow that to notify another rule, when it results in a change. So you add in:
notify => "Name of rule"
# or
notify => [ "Name of rule", "Name of another rule" ]
You could also express dependencies the other way round:
shell { name => "Do stuff",
command => "wc -l /etc/passwd > /tmp/foo",
requires => [ "Rule 1", "Rule 2"] }
Anyway the end result is a simple syntax which allows you to do things; I wrote a file to allow me to take a clean system and configure it to run a simple golang application in an hour or so.
The downside? Well the obvious one is that there's no support for setting up cron jobs, setting up docker images, MySQL usernames/passwords, etc. Just a core set of primitives.
Adding new things is easy, but also an endless job. So I added the ability to run external/binary plugins stored outside the project. To support that is simple with the syntax we have:
- We pass the parameters, as JSON, to STDIN of the binary.
- We read the result from STDOUT
- Did the rule result in a change to the system?
- Or was it a NOP?
All good. People can write modules, if they like, and they can do that in any language they like.
Fun times.
We'll call it marionette since it's all puppet-inspired:
And that concludes this irregular update.
Tags: github, marionette, markdownshare, oodi, puppet, university
|
28 July 2020 21:00
Sometimes I enjoy reading the source code to projects I like, use, or am about to install for the first time. This was something I used to do on a very regular basis, looking for security issues to report. Nowadays I don't have so much free time, but I still like to inspect the source code to new applications I install, and every now and again I'll find the time to look at the source to random projects.
Reading code is good. Reading code is educational.
One application I've looked at multiple times is redis, which is a great example of clean and well-written code. That said when reading the redis codebase I couldn't help noticing that there were a reasonably large number of typos/spelling mistakes in the comments, so I submitted a pull-request:
Sadly that particular pull-request didn't receive too much attention, although a previous one updating the configuration file was accepted. I was recently reminded of these pull-requests when I was when I was doing some other work. So I figured I'd have a quick scan of a couple of other utilities.
In the past I'd just note spelling mistakes when I came across them, usually I'd be opening each file in a project one by one and reading them from top to bottom. (Sometimes I'd just open files in emacs and run "M-x ispell-comments-and-strings", but more often I'd just notice them with my eyes). It did strike me that if I were to do this in a more serious fashion it would be good to automate it.
So this time round I hacked up a simple "dump comments" utility, which would scan named files and output the contents of any comments (be they single-line, or multi-line). Once I'd done that I could spell-check easily:
$ go run dump-comments.go *.c > comments
$ aspell -c comments
Anyway the upshot of that was a pull-request against git:
We'll see if that makes its way live sometime. In case I get interested in doing this again I've updated my sysbox-utility collection to have a comments sub-command. That's a little more robust and reliable than my previous hack:
$ sysbox comments -pretty=true $(find . -name '*.c')
..
..
The comments sub-command has support for:
- Single-line comments, for C, as prefixed with
//.
- Multi-line comments, for C++, as between
/* and */.
- Single-line comments, for shell, as prefixed with
#.
- Lua comments, both single-line (prefixed with
--) and multiline between --[[ and --]].
Adding new support would be trivial, I just need a start and end pattern to search against. Pull-requests welcome:
Tags: git, github, redis, sysbox
|
16 September 2020 21:00
Four years ago somebody posted a comment-thread describing how you could start writing a little reverse-polish calculator, in C, and slowly improve it until you had written a minimal FORTH-like system:
At the time I read that comment I'd just hacked up a simple FORTH REPL of my own, in Perl, and I said "thanks for posting". I was recently reminded of this discussion, and decided to work through the process.
Using only minimal outside resources the recipe worked as expected!
The end-result is I have a working FORTH-lite, or FORTH-like, interpreter written in around 2000 lines of golang! Features include:
- Reverse-Polish mathematical operations.
- Comments between
( and ) are ignored, as expected.
- Single-line comments
\ to the end of the line are also supported.
- Support for floating-point numbers (anything that will fit inside a
float64).
- Support for printing the top-most stack element (
., or print).
- Support for outputting ASCII characters (
emit).
- Support for outputting strings (
." Hello, World ").
- Support for basic stack operations (
drop, dup, over, swap)
- Support for loops, via
do/loop.
- Support for conditional-execution, via
if, else, and then.
- Load any files specified on the command-line
- If no arguments are included run the REPL
- A standard library is loaded, from the present directory, if it is present.
To give a flavour here we define a word called star which just outputs a single start-character:
: star 42 emit ;
Now we can call that (NOTE: We didn't add a newline here, so the REPL prompt follows it, that's expected):
> star
*>
To make it more useful we define the word "stars" which shows N stars:
> : stars dup 0 > if 0 do star loop else drop then ;
> 0 stars
> 1 stars
*> 2 stars
**> 10 stars
**********>
This example uses both if to test that the parameter on the stack was greater than zero, as well as do/loop to handle the repetition.
Finally we use that to draw a box:
> : squares 0 do over stars cr loop ;
> 4 squares
****
****
****
****
> 10 squares
**********
**********
**********
**********
**********
**********
**********
**********
**********
**********
For fun we allow decompiling the words too:
> #words 0 do dup dump loop
..
Word 'square'
0: dup
1: *
Word 'cube'
0: dup
1: square
2: *
Word '1+'
0: store 1.000000
2: +
Word 'test_hot'
0: store 0.000000
2: >
3: if
4: [cond-jmp 7.000000]
6: hot
7: then
..
Anyway if that is at all interesting feel free to take a peak. There's a bit of hackery there to avoid the use of return-stacks, etc. Compared to gforth this is actually more featureful in some areas:
- I allow you to use conditionals in the REPL - outside a word-definition.
- I allow you to use loops in the REPL - outside a word-definition.
Find the code here:
Tags: forth, github, go, golang, hackernews
|
22 September 2020 13:00
So my previous post was all about implementing a simple FORTH-like language. Of course the obvious question is then "What do you do with it"?
So I present one possible use - turtle-graphics:
\ Draw a square of the given length/width
: square
dup dup dup dup
4 0 do
forward
90 turn
loop
;
\ pen down
1 pen
\ move to the given pixel
100 100 move
\ draw a square of width 50 pixels
50 square
\ save the result (png + gif)
save
Exciting times!
Tags: forth, github, go, golang, turtle
|
3 October 2020 13:00
Recently I've been writing a couple of simple compilers, which take input in a particular format and generate assembly language output. This output can then be piped through gcc to generate a native executable.
Public examples include this trivial math compiler and my brainfuck compiler.
Of course there's always the nagging thought that relying upon gcc (or nasm) is a bit of a cheat. So I wondered how hard is it to write an assembler? Something that would take assembly-language program and generate a native (ELF) binary?
And the answer is "It isn't hard, it is just tedious".
I found some code to generate an ELF binary, and after that assembling simple instructions was pretty simple. I remember from my assembly-language days that the encoding of instructions can be pretty much handled by tables, but I've not yet gone into that.
(Specifically there are instructions like "add rax, rcx", and the encoding specifies the source/destination registers - with different forms for various sized immediates.)
Anyway I hacked up a simple assembler, it can compile a.out from this input:
.hello DB "Hello, world\n"
.goodbye DB "Goodbye, world\n"
mov rdx, 13 ;; write this many characters
mov rcx, hello ;; starting at the string
mov rbx, 1 ;; output is STDOUT
mov rax, 4 ;; sys_write
int 0x80 ;; syscall
mov rdx, 15 ;; write this many characters
mov rcx, goodbye ;; starting at the string
mov rax, 4 ;; sys_write
mov rbx, 1 ;; output is STDOUT
int 0x80 ;; syscall
xor rbx, rbx ;; exit-code is 0
xor rax, rax ;; syscall will be 1 - so set to xero, then increase
inc rax ;;
int 0x80 ;; syscall
The obvious omission is support for "JMP", "JMP_NZ", etc. That's painful because jumps are encoded with relative offsets. For the moment if you want to jump:
push foo ; "jmp foo" - indirectly.
ret
:bar
nop ; Nothing happens
mov rbx,33 ; first syscall argument: exit code
mov rax,1 ; system call number (sys_exit)
int 0x80 ; call kernel
:foo
push bar ; "jmp bar" - indirectly.
ret
I'll update to add some more instructions, and see if I can use it to handle the output I generate from a couple of other tools. If so that's a win, if not then it was a fun learning experience:
Tags: asm, assembly, github, go, golang
|
21 June 2022 13:00
Recently I was reading Antirez's piece TCL the Misunderstood again, which is a nice defense of the utility and value of the TCL language.
TCL is one of those scripting languages which used to be used a hell of a lot in the past, for scripting routers, creating GUIs, and more. These days it quietly lives on, but doesn't get much love. That said it's a remarkably simple language to learn, and experiment with.
Using TCL always reminds me of FORTH, in the sense that the syntax consists of "words" with "arguments", and everything is a string (well, not really, but almost. Some things are lists too of course).
A simple overview of TCL would probably begin by saying that everything is a command, and that the syntax is very free. There are just a couple of clever rules which are applied consistently to give you a remarkably flexible environment.
To get started we'll set a string value to a variable:
set name "Steve Kemp"
=> "Steve Kemp"
Now you can output that variable:
puts "Hello, my name is $name"
=> "Hello, my name is Steve Kemp"
OK, it looks a little verbose due to the use of set, and puts is less pleasant than print or echo, but it works. It is readable.
Next up? Interpolation. We saw how $name expanded to "Steve Kemp" within the string. That's true more generally, so we can do this:
set print pu
set me ts
$print$me "Hello, World"
=> "Hello, World"
There "$print" and "$me" expanded to "pu" and "ts" respectively. Resulting in:
puts "Hello, World"
That expansion happened before the input was executed, and works as you'd expect. There's another form of expansion too, which involves the [ and ] characters. Anything within the square-brackets is replaced with the contents of evaluating that body. So we can do this:
puts "1 + 1 = [expr 1 + 1]"
=> "1 + 1 = 2"
Perhaps enough detail there, except to say that we can use { and } to enclose things that are NOT expanded, or executed, at parse time. This facility lets us evaluate those blocks later, so you can write a while-loop like so:
set cur 1
set max 10
while { expr $cur <= $max } {
puts "Loop $cur of $max"
incr cur
}
Anyway that's enough detail. Much like writing a FORTH interpreter the key to implementing something like this is to provide the bare minimum of primitives, then write the rest of the language in itself.
You can get a usable scripting language with only a small number of the primitives, and then evolve the rest yourself. Antirez also did this, he put together a small TCL interpreter in C named picol:
Other people have done similar things, recently I saw this writeup which follows the same approach:
So of course I had to do the same thing, in golang:
My code runs the original code from Antirez with only minor changes, and was a fair bit of fun to put together.
Because the syntax is so fluid there's no complicated parsing involved, and the core interpreter was written in only a few hours then improved step by step.
Of course to make a language more useful you need I/O, beyond just writing to the console - and being able to run the list-operations would make it much more useful to TCL users, but that said I had fun writing it, it seems to work, and once again I added fuzz-testers to the lexer and parser to satisfy myself it was at least somewhat robust.
Feedback welcome, but even in quiet isolation it's fun to look back at these "legacy" languages and recognize their simplicity lead to a lot of flexibility.
Tags: github, golang, tcl
|
1 July 2022 19:00
So my previous post introduced a trivial interpreter for a TCL-like language.
In the past week or two I've cleaned it up, fixed a bunch of bugs, and added 100% test-coverage. I'm actually pretty happy with it now.
One of the reasons for starting this toy project was to experiment with how easy it is to extend the language using itself
Some things are simple, for example replacing this:
puts "3 x 4 = [expr 3 * 4]"
With this:
Just means defining a function (proc) named *. Which we can do like so:
proc * {a b} {
expr $a * $b
}
(Of course we don't have lists, or variadic arguments, so this is still a bit of a toy example.)
Doing more than that is hard though without support for more primitives written in the parent language than I've implemented. The obvious thing I'm missing is a native implementation of upvalue, which is TCL primitive allowing you to affect/update variables in higher-scopes. Without that you can't write things as nicely as you would like, and have to fall back to horrid hacks or be unable to do things.
# define a procedure to run a body N times
proc repeat {n body} {
set res ""
while {> $n 0} {
decr n
set res [$body]
}
$res
}
# test it out
set foo 12
repeat 5 { incr foo }
# foo is now 17 (i.e. 12 + 5)
A similar story implementing the loop word, which should allow you to set the contents of a variable and run a body a number of times:
proc loop {var min max bdy} {
// result
set res ""
// set the variable. Horrid.
// We miss upvalue here.
eval "set $var [set min]"
// Run the test
while {<= [set "$$var"] $max } {
set res [$bdy]
// This is a bit horrid
// We miss upvalue here, and not for the first time.
eval {incr "$var"}
}
// return the last result
$res
}
loop cur 0 10 { puts "current iteration $cur ($min->$max)" }
# output is:
# => current iteration 0 (0-10)
# => current iteration 1 (0-10)
# ...
That said I did have fun writing some simple test-cases, and implementing assert, assert_equal, etc.
In conclusion I think the number of required primitives needed to implement your own control-flow, and run-time behaviour, is a bit higher than I'd like. Writing switch, repeat, while, and similar primitives inside TCL is harder than creating those same things in FORTH, for example.
Tags: github, golang, tcl
|
15 July 2022 13:00
Recently I've been working with simple/trivial scripting languages, and I guess I finally reached a point where I thought "Lisp? Why not". One of the reasons for recent experimentation was thinking about the kind of minimalism that makes implementing a language less work - being able to actually use the language to write itself.
FORTH is my recurring example, because implementing it mostly means writing a virtual machine which consists of memory ("cells") along with a pair of stacks, and some primitives for operating upon them. Once you have that groundwork in place you can layer the higher-level constructs (such as "for", "if", etc).
Lisp allows a similar approach, albeit with slightly fewer low-level details required, and far less tortuous thinking. Lisp always feels higher-level to me anyway, given the explicit data-types ("list", "string", "number", etc).
Here's something that works in my toy lisp:
;; Define a function, `fact`, to calculate factorials (recursively).
(define fact (lambda (n)
(if (<= n 1)
1
(* n (fact (- n 1))))))
;; Invoke the factorial function, using apply
(apply (list 1 2 3 4 5 6 7 8 9 10)
(lambda (x)
(print "%s! => %s" x (fact x))))
The core language doesn't have helpful functions to filter lists, or build up lists by applying a specified function to each member of a list, but adding them is trivial using the standard car, cdr, and simple recursion. That means you end up writing lots of small functions like this:
(define zero? (lambda (n) (if (= n 0) #t #f)))
(define even? (lambda (n) (if (zero? (% n 2)) #t #f)))
(define odd? (lambda (n) (! (even? n))))
(define sq (lambda (x) (* x x)))
Once you have them you can use them in a way that feels simple and natural:
(print "Even numbers from 0-10: %s"
(filter (nat 11) (lambda (x) (even? x))))
(print "Squared numbers from 0-10: %s"
(map (nat 11) (lambda (x) (sq x))))
This all feels very sexy and simple, because the implementations of map, apply, filter are all written using the lisp - and they're easy to write.
Lisp takes things further than some other "basic" languages because of the (infamous) support for Macros. But even without them writing new useful functions is pretty simple. Where things struggle? I guess I don't actually have a history of using lisp to actually solve problems - although it's great for configuring my editor..
Anyway I guess the journey continues. Having looked at the obvious "minimal core" languages I need to go further afield:
I'll make an attempt to look at some of the esoteric programming languages, and see if any of those are fun to experiment with.
Tags: github, lisp
|
23 September 2022 19:00
In my previous post I introduced yet another Lisp interpreter. When it was posted there was no support for macros.
Since I've recently returned from a visit to the UK, and caught COVID-19 while I was there, I figured I'd see if my brain was fried by adding macro support.
I know lisp macros are awesome, it's one of those things that everybody is told. Repeatedly. I've used macros in my emacs programming off and on for a good few years, but despite that I'd not really given them too much thought.
If you know anything about lisp you know that it's all about the lists, the parenthesis, and the macros. Here's a simple macro I wrote:
(define if2 (macro (pred one two)
`(if ~pred (begin ~one ~two))))
The standard lisp if function allows you to write:
(if (= 1 a) (print "a == 1") (print "a != 1"))
There are three arguments supplied to the if form:
- The test to perform.
- A single statement to execute if the test was true.
- A single statement to execute if the test was not true.
My if2 macro instead has three arguments:
- The test to perform.
- The first statement to execute if the test was true.
- The second statement to execute if the test was true.
- i.e. There is no "else", or failure, clause.
This means I can write:
(if2 blah
(one..)
(two..))
Rather than:
(if blah
(begin
(one..)
(two..)))
It is simple, clear, and easy to understand and a good building-block for writing a while function:
(define while-fun (lambda (predicate body)
(if2 (predicate)
(body)
(while-fun predicate body))))
There you see that if the condition is true then we call the supplied body, and then recurse. Doing two actions as a result of the single if test is a neat shortcut.
Of course we need to wrap that up in a macro, for neatness:
(define while (macro (expression body)
(list 'while-fun
(list 'lambda '() expression)
(list 'lambda '() body))))
Now we're done, and we can run a loop five times like so:
(let ((a 5))
(while (> a 0)
(begin
(print "(while) loop - iteration %s" a)
(set! a (- a 1) true))))
Output:
(while) loop - iteration 5
(while) loop - iteration 4
(while) loop - iteration 3
(while) loop - iteration 2
(while) loop - iteration 1
We've gone from using lists to having a while-loop, with a couple of simple macros and one neat recursive function.
There are a lot of cute things you can do with macros, and now I'm starting to appreciate them a little more. Of course it's not quite as magical as FORTH, but damn close!
Tags: forth, github, lisp
|
8 October 2022 15:00
Over the past few months (years?) I've posted on my blog about the various toy interpreters I've written.
I've used a couple of scripting languages/engines in my professional career, but in public I think I've implemented
- BASIC
- evalfilter
- FORTH
- Lisp
- Monkey
- TCL
Each of these works in similar ways, and each of these filled a minor niche, or helped me learn something new. But of course there's always a question:
In the real world? It just doesn't matter. For me. But I was curious, so I hacked up a simple benchmark of calculating 12! (i.e. The factorial of 12).
The specific timings will vary based on the system which runs the test(s), but there's no threading involved so the relative performance is probably comparable.
Anyway the benchmark is simple, and I did it "fairly". By that I mean that I didn't try to optimize any particular test-implementation, I just wrote it in a way that felt natural.
The results? Evalfilter wins, because it compiles the program into bytecode, which can be executed pretty quickly. But I was actually shocked ("I wrote a benchmark; The results will blow your mind!") at the second and third result:
BenchmarkEvalFilterFactorial-4 61542 17458 ns/op
BenchmarkFothFactorial-4 44751 26275 ns/op
BenchmarkBASICFactorial-4 36735 32090 ns/op
BenchmarkMonkeyFactorial-4 14446 85061 ns/op
BenchmarkYALFactorial-4 2607 456757 ns/op
BenchmarkTCLFactorial-4 292 4085301 ns/op
here we see that FOTH, my FORTH implementation, comes second. I guess this is an efficient interpreter too, bacause that too is essentially "bytecode". (Looking up words in a dictionary, which really maps to indexes to other words. The stack operations are reasonably simple and fast too.)
Number three? BASIC? I expected better from the other implementations to be honest. BASIC doesn't even use an AST (in my implementation), just walks tokens. I figured the TCO implemented by my lisp would make that number three.
Anyway the numbers mean nothing. Really. But still interesting.
Tags: basic, forth, github, lisp, tcl
|
24 June 2023 13:00
So my previous post documented a couple of simple "scripting languages" for small computers, allowing basic operations in a compact/terse fashion.
I mentioned that I might be tempted to write something similar for CP/M, in Z80 assembly, and the result is here:
To sum up it allows running programs like this:
0m 16k{rP _ _}
C3 03 EA 00 00 C3 06 DC 00 00 00 00 00 00 00 00
Numbers automatically get saved to the A-register, the accumulator. In addition to that there are three dedicated registers:
- M-register is used to specify which RAM address to read/write from.
- The instruction
m copies the value of accumulator to the M-register.
- The instruction
M copies the value of the M-register to the accumulator.
- K-register is used to execute loops.
- The instruction
k copies the value of accumulator to the K-register.
- The instruction
K copies the value of the K-register to the accumulator.
- U-register is used to specify which port to run I/O input and output from.
- The instruction
u copies the value of accumulator to the U-register.
- The instruction
U copies the value of the U-register to the accumulator.
So the program above:
0m
0 is stored in the accumulator.m copies the value of the accumulator to the M-register. 16k
16 is stored in the accumulator.k copies the value of the accumulator (16) to the K-register, which is used for looping. { - Starts a loop.
- The K-register is decremented by one.
- If the K-register is greater than zero the body is executed, up to the closing brace.
- Loop body:
r Read a byte to the accumulator from the address stored in the M-register, incrementing that register in the process.P: Print the contents of the accumulator._ _ Print a space.
} End of the loop, and end of the program.
TLDR: Dump the first sixteen bytes of RAM, at address 0x0000, to the console.
Though this program allows delays, RAM read/write, I/O port input and output, as well as loops it's both kinda fun, and kinda pointless. I guess you could spend hours flashing lights and having other similar fun. But only if you're like me!
All told the code compiles down to about 800 bytes and uses less than ten bytes of RAM to store register-state. It could be smaller with some effort, but it was written a bit adhoc and I think I'm probably done now.
Tags: assembly, cpm, github, z80
|
|
